简介
LangChain是一个用于开发由语言模型驱动的应用程序的框架。
主要功能:
调用语言模型
将不同数据源接入到语言模型的交互中
允许语言模型与运行环境交互
基本架构

LangChain中提供的模块
Modules:支持的模型类型和集成。
Prompt:提示词管理、优化和序列化。
Memory:内存是指在链/代理调用之间持续存在的状态。
Indexes:当语言模型与特定于应用程序的数据相结合时,会变得更加强大-此模块包含用于加载、查询和更新外部数据的接口和集成。
Chain:链是结构化的调用序列(对LLM或其他实用程序)。
Agents:代理是一个链,其中LLM在给定高级指令和一组工具的情况下,反复决定操作,执行操作并观察结果,直到高级指令完成。
Callbacks:回调允许您记录和流式传输任何链的中间步骤,从而轻松观察、调试和评估应用
程序的内部。
应用场景
- 文档问答
- 查询数据表格(CSV、SQL、DataFrame等)
- API交互、信息提取、文档总结等
Model I/O
四个核心组件:
- Prompts 提示词
- Chat Models 聊天模型
- 擅长对话
- LLMs 纯文本模型
- 擅长理解和合成文本方面,例如总结文档、PDF、概念页面等
- Output parsers 输出转换器
📌Chat Models 和 LLMs 的区别:
Chat models和LLMs都是LangChain中的语言模型抽象,但是LLMs是纯语言模型,Chat models是针对对话做了优化的聊天模型
Agents
大型语言模型(LLMs)非常强大,但它们缺乏“最笨”的计算机程序可以轻松处理的特定能力。LLM 对逻辑推理、计算和检索外部信息的能力较弱,这与最简单的计算机程序形成对比。例如,语言模型无法准确回答简单的计算问题,还有当询问最近发生的事件时,其回答也可能过时或错误,因为无法主动获取
最新信息。这是由于当前语言模型仅依赖预训练数据,与外界“断开”。要克服这一缺陷, LangChain 框
架提出了 “代理”(Agent) 的解决方案。
Agent作为语言模型的外部模块,可提供计算、逻辑、检索等功能的支持,使语言模型获得异常强大的推理和获取信息的超能力。
Agents的核心思想是使用语言模型来选择要采取的一系列Action
在langchain中,一系列Action被硬编码(在代码中)。
在Agents中,语言模型被用作推理引擎来确定要采取哪些操作以及按什么顺序。
不同Agents的区别:不同的推理提示风格、不同的编码输入方式以及不同的解析输出方式。
基本概念
Schema
构建代理的核心组件
AgentAction即Action,表示代理执行的操作,通常表示调用tools- 我们将想让对Agents的操作封装成Action(tools),再让Agents在被调用时选择应该使用哪些tools
- 在
AgentAction中有两个属性:tool和tool_input,分别代表工具的名字和工具输入
AgentFinishAgents返回的最终结果Intermediate Steps中间步骤。代表AgentAction以及当前Agents运行的相应输出
Agent
Agent InputsAgents的输入,键值对类型- required:
intermediate_steps
- required:
Agent OutputsAgents的响应,分为Union[AgentAction, List[AgentAction], AgentFinish]- 输出解析器负责获取原始 LLM 输出并将其转换为这三种类型之一
demo:
1 | agent = ( |
Agents API
AgentExecutor重复调用Agents并执行工具- 封装了各种错误处理、日志等
Tools
工具是代理可以调用的功能。 Tool 抽象由两个组件组成:
工具 API 的目标是比使用通用文本完成或聊天 API 更可靠地返回有效且有用的工具调用。
- schema
- function
设计Agents的关键:
- 让Agents正确的使用tools
- 以对代理最有帮助的方式描述工具
Agent Type
介绍几个常用的Agent Type
ReAct:LLM 可以循环进行 Reasoning 和 Action 步骤的过程。它启用了一个多步骤的过程来识别答案。
Prompt
提示词工程和模型微调的区别:
微调
- 定义:针对预先训练的语言模型,在特定任务的少量数据集上对其进行进一步训练
- 适用场景:当任务或域定义明确,并且有足够的标记数据可供训练时,通常使用微调过程
提示词工程
- 涉及设计自然语言提示或指令,可以指导语言模型执行特定任务
- 最适合需要高精度和明确输出的任务。提示工程可用于制作引发所需输出的查询
Memory
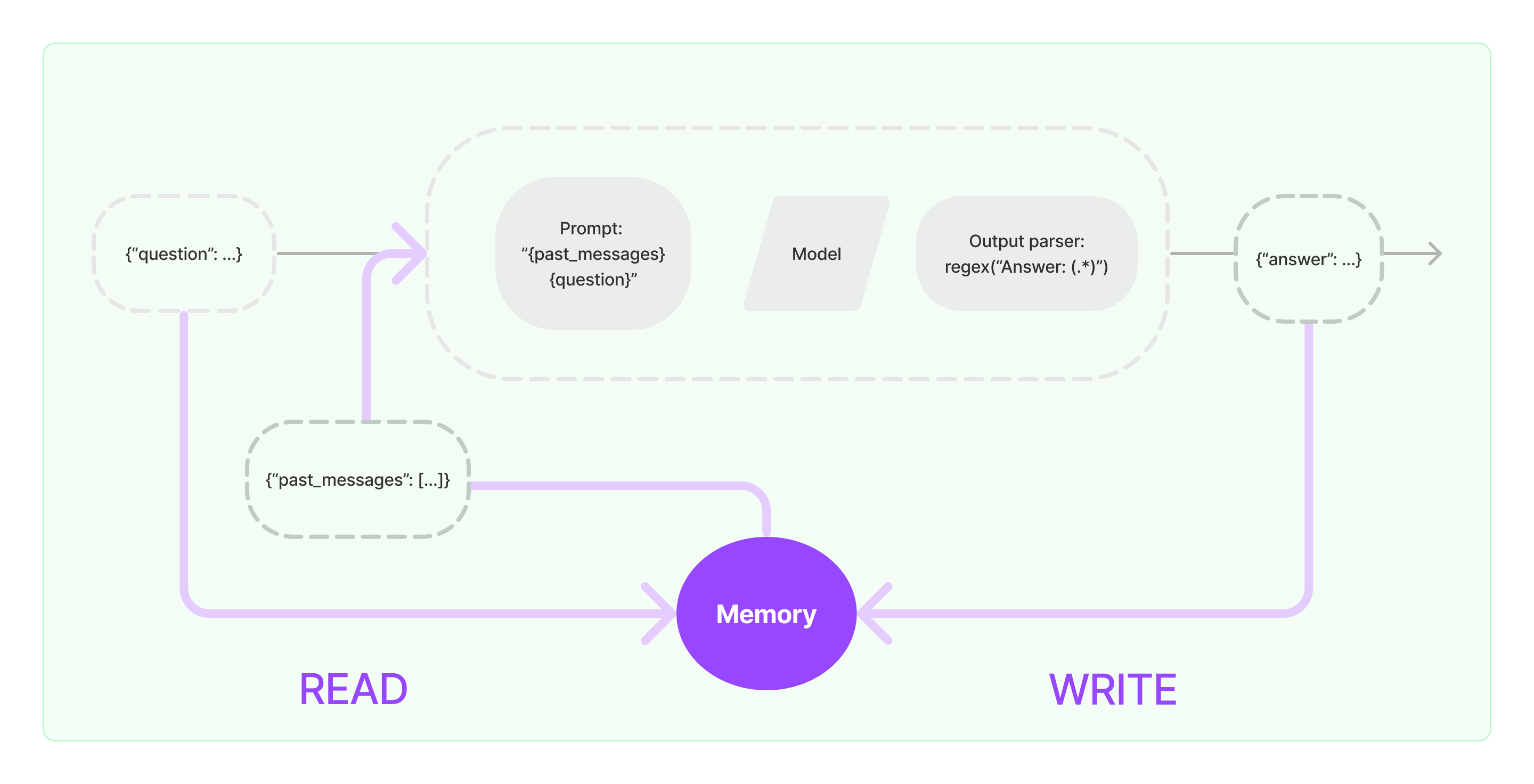
四种主要储存模块:
ConversationBufferMemory对话缓存ConversationTokenBufferMemory按窗口缓存ConversationTokenBufferMemory按令牌缓存ConversationSummaryBufferMemory按摘要缓存
最常见的内存类型之一涉及返回聊天消息列表。这些可以作为单个字符串返回,全部连接在一起(当它们被传递到 LLMs 时有用)或 ChatMessages 列表(当传递到 ChatModels 时有用)。
默认情况下,它们作为单个字符串返回。为了作为消息列表返回,您可以设置 return_messages=True

Chains
链是指调用序列 - 即 LLM、Tools还是数据预处理步骤的先后顺序。主要支持的方法是使用 LCEL。
LCEL Chains
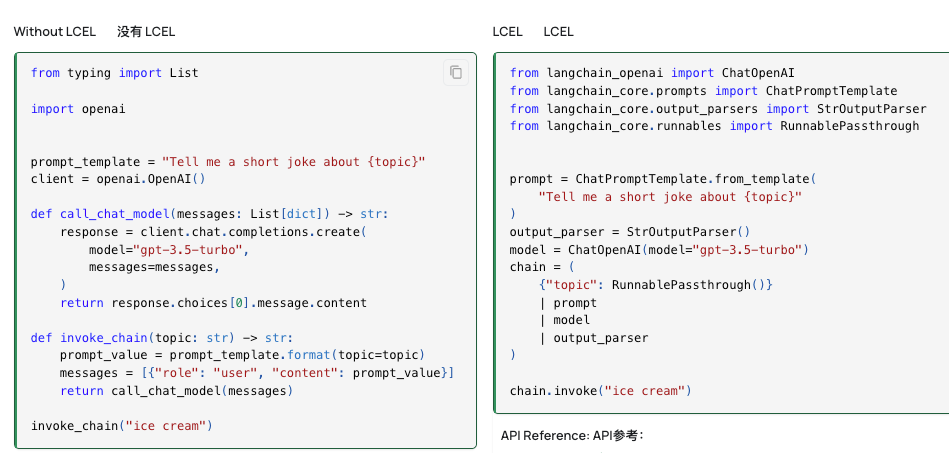
LangChain Expression Language(LCEL)可以轻松地从基本组件构建复杂的链,并支持开箱即用的功能,例如流式传输、并行性和日志记录,最基本和常见的用例是将Prompt和LLM链接在一起。
1 | chain = prompt | model | output_parser |
https://python.langchain.com/v0.1/docs/expression_language/get_started/
意义:组合大模型调用中不相关的部分,让开发者省去胶水代码
下面举一些简单的栗子:
模型调用:
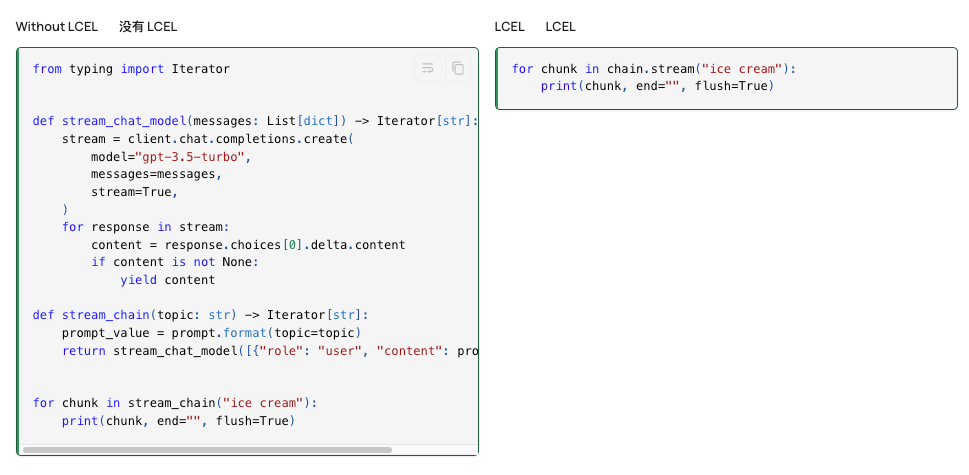
Stream流:
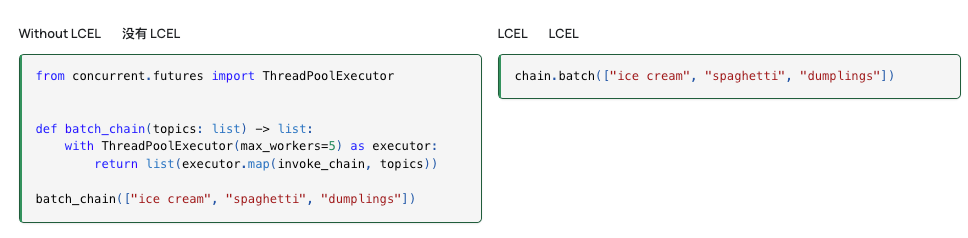
Batch批处理:
异步调用:

RAG
全称Retrieval Augmented Generation (RAG)
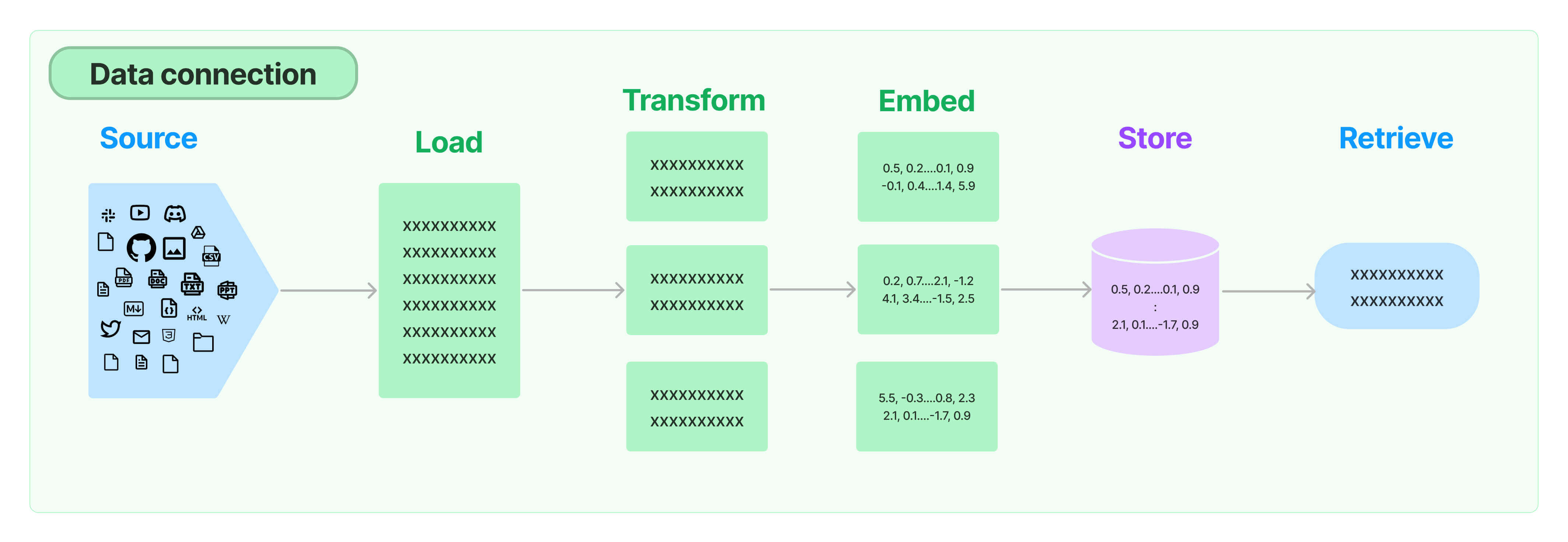
核心组件:
- Document loaders文档加载器
- Text Splitting文本分割器,将大文档分割(或分块)为更小的块。
- Text Embedding models嵌入模型,用于将文档嵌入到Vector stores中,主要有两种常用方式:
- text2vector
- llm
- Retrievers检索器,用于在数据源中检索相关信息
- Indexing数据库索引,用于检索
Retrievers检索
相关算法:
基本语义相似度(Basicsemanticsimilarity)
最大边际相关性(Maximummarginalrelevance,MMR)
过滤元数据
LLM辅助检索 SelfQueryRetriever
压缩 ContextualCompressionRetriever
- 工作原理:先使用标准向量检索获得候选文档,然后基于查询语句的语义,使用语言模型压缩这些文档,只保留与问题相关的部分
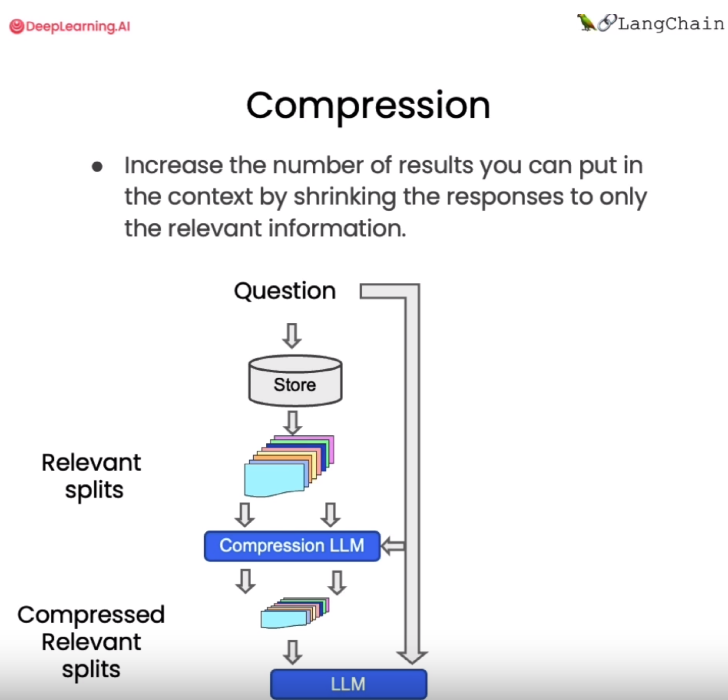
- 工作原理:先使用标准向量检索获得候选文档,然后基于查询语句的语义,使用语言模型压缩这些文档,只保留与问题相关的部分
其他类型的检索:
vetordb 并不是唯一一种检索文档的工具。 LangChain 还提供了其他检索文档的方式,例如: TF-IDF 或 SVM 。
对话检索链
检索链类型
通过LangChain创建一个检索问答链,对检索到的文档进行问题回答。检索问答链的输入包含以下
- llm大语言模型
chain_type指定传入链(用于将文档传递到 LLM 的上下文窗口中)类型- Stuff:只需将所有文档“塞”到一个提示中即可,这是最简单的方法
- API:create_stuff_documents_chain
- Map-reduce:将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的
- MapReduceDocumentsChain
- Refine
- 循环许多文档,实际上是迭代的,建立在先前文档的答案之上,非常适合前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。
- Stuff:只需将所有文档“塞”到一个提示中即可,这是最简单的方法


示例
1 | from langchain.chains.combine_documents.stuff import StuffDocumentsChain |