最近工作中用到了这个技术「GraphQL」,本文记录一下入门学习过程
1 基础概念
1.1 操作类型 Operation Type
query:查询数据,相当于CRUD 中的 Rmutation:变更,对数据进行变更,比如增加、删除、修改,CRUD 中的 CUDsubstription:订阅,当数据发生更改,进行消息推送
1.2 对象类型和标量类型 Object Type & Scalar Type
- 对象类型:用户在 schema 中定义的
type
- 标量类型:GraphQL 中内置有一些标量类型
String、Int、Float、Boolean、ID,用户也可以定义自己的标量类型
例如:
1
2
3
4
| type MetaData {
fileName: String!
fileId: ID
}
|
其中MetaData是对象类型,String、ID等则是标量类型,!表示非空标量
如果一个 GraphQL 服务接受到了一个 query,那么这个 query 将从 Root Query 开始查找,找到对象类型时则使用它的解析函数 Resolver 来获取内容,如果返回的是对象类型则继续使用解析函数获取内容,如果返回的是标量类型则结束获取,直到找到最后一个标量类型。
1.3 模式 Schema
Schema定义了字段的类型、数据的结构,描述了接口数据请求的规则,Schema 使用一个简单的强类型模式语法,称为模式描述语言(Schema Definition Language, SDL)
如下是一个Schema的demo:
1
2
3
4
5
6
7
8
9
10
11
12
| type Query {
metaData(fileId: ID): MetaData
}
type Mutation {
createMetaData(fileId: ID, fileName: String, fileType: String): MetaData
}
type MetaData {
fileName: String!
fileType: String
}
|
Schema 文件从 Query、Mutation、Subscription 入口开始定义了各个对象类型或标量类型,这些字段的类型也可能是其他的对象类型或标量类型,组成一个树形结构,而用户在向服务端发送请求的时候,沿着这个树选择一个或多个分支就可以获取多组信息。
注意:在 Query 查询字段时,是并行执行的,而在 Mutation 变更的时候,是线性执行,一个接着一个,防止同时变更带来的竞态问题,比如说我们在一个请求中发送了两个 Mutation,那么前一个将始终在后一个之前执行。
1.4 解析函数 Resolver
前端请求信息到达后端之后,需要由解析函数 Resolver 来提供数据:
对应的同名的解析函数应该是这样的:
1
2
3
4
5
| Query: {
hello (parent, args, context, info) {
return ...
}
}
|
解析函数接受四个参数,分别为
parent:当前上一个解析函数的返回值args:查询中传入的参数context:提供给所有解析器的上下文信息info:一个保存与当前查询相关的字段特定信息以及 schema 详细信息的值
解析函数的返回值可以是一个具体的值,也可以是 Promise 或 Promise 数组。
1.5 请求格式
下面演示如何通过 Get/Post 方式来执行下面的 GraphQL 查询:
查询文档
1
2
3
4
5
| query {
me {
name
}
}
|
Get/Post请求方式:
1
2
3
4
5
6
7
8
9
|
http:
{
"query": "{me{name}}",
"operationName": "",
"variables": { "name": "value", ... }
}
|
标准的 GraphQL POST 请求应当在 HTTP header 中声明 Content-Type: application/json,并且使用 JSON 格式的内容。
返回的格式
1
2
3
4
5
6
7
8
9
|
{
"data": { ... }
}
{
"errors": [ ... ]
}
|
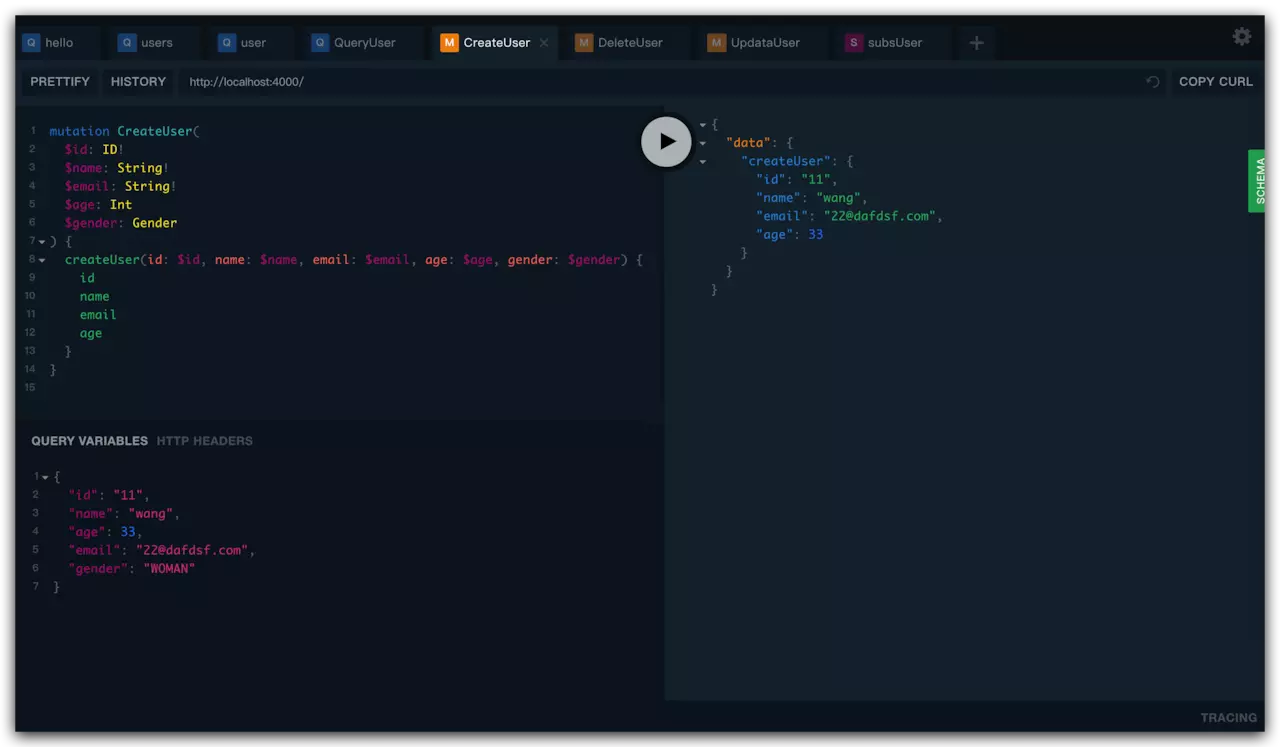
GraphQL也提供了方便的图形化界面帮助构建GraphQL请求:
左边是请求信息栏,左下是请求参数栏和请求头设置栏,右边是返回参数栏
2 GraphQL-Java
先看一下官网Demo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class HelloWorld {
public static void main(String[] args) {
String schema = "type Query{hello: String} schema{query: Query}";
SchemaParser schemaParser = new SchemaParser();
TypeDefinitionRegistry typeDefinitionRegistry = schemaParser.parse(schema);
RuntimeWiring runtimeWiring = new RuntimeWiring()
.type("Query", builder -> builder.dataFetcher("hello", new StaticDataFetcher("world")))
.build();
SchemaGenerator schemaGenerator = new SchemaGenerator();
GraphQLSchema graphQLSchema = schemaGenerator.makeExecutableSchema(typeDefinitionRegistry, runtimeWiring);
GraphQL build = GraphQL.newGraphQL(graphQLSchema).build();
ExecutionResult executionResult = build.execute("{hello}");
System.out.println(executionResult.getData().toString());
}
}
|
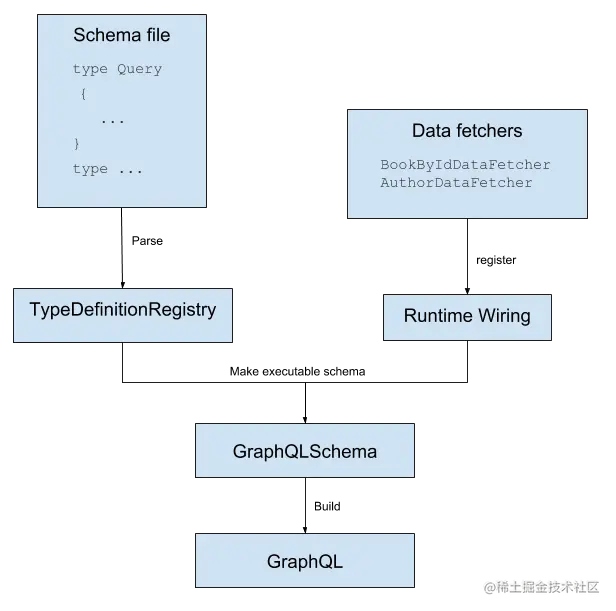
通过这个Demo,我们来看一下GraphQL的实现需要哪些关键组件:
2.1 TypeDefinitionRegistry
类型定义。在Java代码中,通过加载Schema文件或描述,将其解析为TypeDefinitionRegistry。
2.2 RuntimeWiring
运行时织入。仅有Schema及其类型定义还不够,在Java中要实际运行GraphQL,还需要显式指定定义中的每个操作,该触发什么样的行为,相当于Resolver函数
例如,在本例中,builder -> builder.dataFetcher("hello", new StaticDataFetcher("world")表示当查询Query类型下的hello字段时,返回值为”world”。
2.3 GraphQL
核心组件。GraphQL实例是我们使用GraphQL最关键的组件,负责对GraphQL请求进行响应
在结合前面TypeDefinitionRegistry和RuntimeWiring的基础上,生成的可运行的GraphQL实例
2.4 ExecutionResult
每次执行GraphQL操作时,返回的结果对象。
其中包含error字段,用于保存执行过程中的报错信息;data字段,用于获取执行结果返回值。
2.5 DataFetchers
Schema中的每个字段都有一个DataFethcer与之关联,在查询执行的时候,它会为查询语句中的每个字段调用合适的DataFetcher
DataFetcher是一个接口,核心方法是get(),只有一个DataFetcherEnvironment参数:
1
2
3
4
| public interface DataFetcher<T> {
T get(DataFetchingEnvironment environment) throws Exception;
}
|
DataFetchingEnvironment中包含前端传递的字段参数,DataFetchers复杂根据这些参数查找到对应的数据
下面这张图非常形象画的(虽然不是我画的😆)
3 实践
“Talk is cheap. Show me the code.”
场景:创建一个文件服务器,能够上传和下载文件,并可以保存和查询文件的元数据
先定义一个Scheme文件schema.graphqls:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| type Query {
metaData(fileId: ID): MetaData
}
type Mutation {
createMetaData(fileId: ID, fileName: String, fileType: String): MetaData
}
type MetaData {
fileName: String
fileType: String
}
mutation createMetaData {
createMetaData(fileId: "%s", fileName: "%s", fileType: "%s") {
fileName,
fileType
}
}
query {
metaData(fileId: "%s") {
fileName,
fileType
}
}
|
我们定义一个类GraphQLFactory,用于构建GraphQL实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| @Component
public class GraphQLFactory {
private GraphQL graphQL;
@Autowire
private SpringSQLQueryDataFetcher queryDataFetcher;
@Autowire
private SpringSQLMutationDataFetcher mutationDataFetcher;
@PostConstruct
public void init() throws IOException {
final String schemaString = getGraphQLSchemaResourceAsString("schema.graphqls");
final GraphQLSchema graphQLSchema = buildSchema(schemaString, queryDataFetcher, mutationDataFetcher);
return GraphQL.newGraphQL(graphQLSchema).build();
}
private GraphQLSchema buildSchema(
final @NotNull String schemaString,
final @NotNull DataFetcher<MetaData> queryDataFetcher,
final @NotNull DataFetcher<MetaData> mutationDataFetcher
) {
final TypeDefinitionRegistry typeDefinitionRegistry = new SchemaParser().parse(schemaString);
final RuntimeWiring runtimeWiring = buildWiring(queryDataFetcher, mutationDataFetcher);
final SchemaGenerator schemaGenerator = new SchemaGenerator();
return schemaGenerator.makeExecutableSchema(typeDefinitionRegistry, runtimeWiring);
}
private RuntimeWiring buildWiring() {
return RuntimeWiring.newRuntimeWiring()
.type(newTypeWiring("Query").dataFetcher("metaData", queryDataFetcher))
.type(newTypeWiring("Mutation").dataFetcher("createMetaData", mutationDataFetcher))
.build();
}
@NotNull
public static String getGraphQLSchemaResourceAsString(@NotNull final String resourceName) {
@SuppressWarnings("ConstantConditions")
final Scanner scanner = new Scanner(
Thread
.currentThread()
.getContextClassLoader()
.getResourceAsStream(Objects.requireNonNull(resourceName))
)
.useDelimiter("\\A");
if (scanner.hasNext()) {
return scanner.next();
}
final String message = String.format("GraphQL schema file not found: '%s'", resourceName);
LOG.error(message);
throw new IllegalStateException(message);
}
}
|
接下来我们创建对应的DataFetchers,分别对Schema中定义的createMetaData和metaData方法进行实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public class SpringSQLQueryDataFetcher implements DataFetcher<MetaData> {
@Override
public MetaData get(final DataFetchingEnvironment dataFetchingEnvironment) throws Exception {
final String fileId = dataFetchingEnvironment.getArgument(FILE_ID);
MetaData metaData = getMetaDataByFileId(fileId);
return metaData;
}
}
public class SpringSQLMutationDataFetcher implements DataFetcher<MetaData> {
private static final String FILE_ID = "fileId";
public static final String FILE_NAME = "fileName";
public static final String FILE_TYPE = "fileType";
@Override
public MetaData get(final DataFetchingEnvironment dataFetchingEnvironment) throws Exception {
final String fileId = dataFetchingEnvironment.getArgument(FILE_ID);
final String fileName = dataFetchingEnvironment.getArgument(FILE_NAME);
final String fileType = dataFetchingEnvironment.getArgument(FILE_TYPE);
updateMetaData(fileId, fileName, fileType);
return MetaData.of(
Stream.of(
new AbstractMap.SimpleImmutableEntry<>(FILE_NAME, fileName),
new AbstractMap.SimpleImmutableEntry<>(FILE_TYPE, fileType)
).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue))
);
}
}
|
参考: