1 神经网络
1.1 向量
向量内积和矩阵乘积:

1.2 激活函数
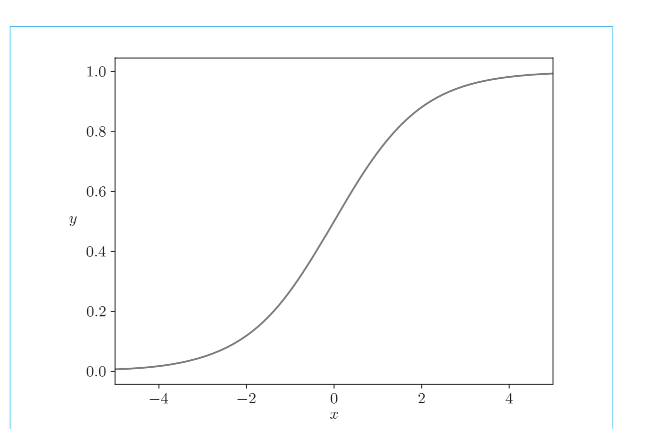
1.2.1 sigmoid
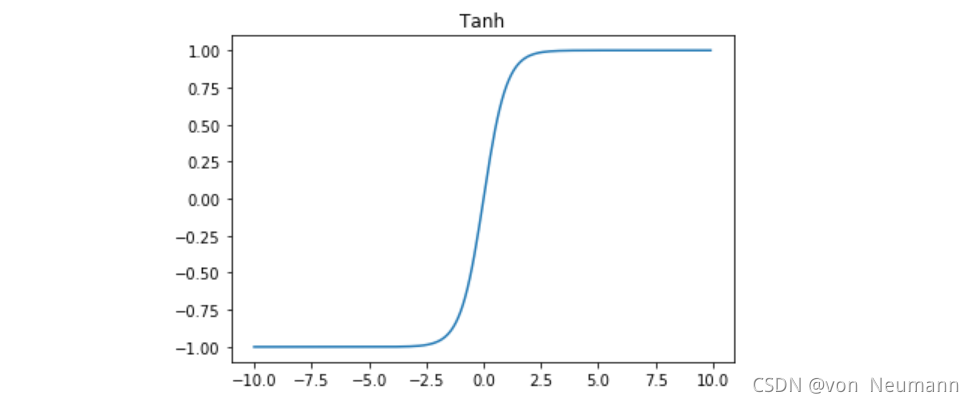
1.2.2 tanh
1.3 Softmax
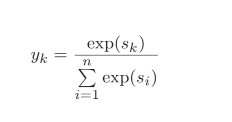
作用:将输出转化为概率和为1的概率分布(概率标准化
交叉熵误差
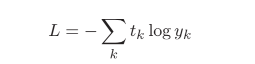
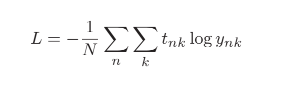
链式法则
链式法则的重要之处在于,无论我们要处理的函数有多复杂(无论复合了多少个函数),都可以根据它们各自的导数来求复合函数的导数。

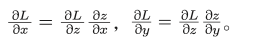
1.4 反向传播
公式
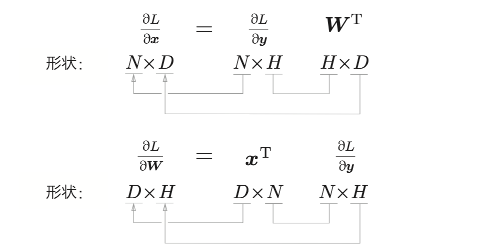
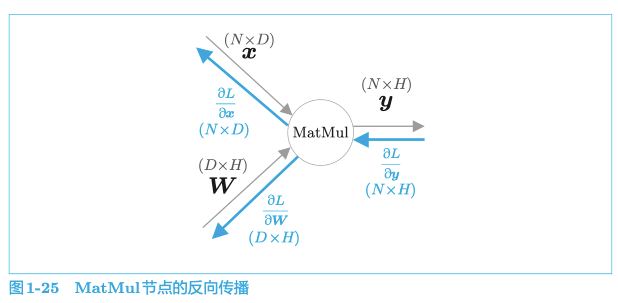
本书将矩阵乘积称为 MatMul(Matrix Multiply)节点。
代码

链式法则:复合函数的导数可以根据各个简单函数的导数来求。
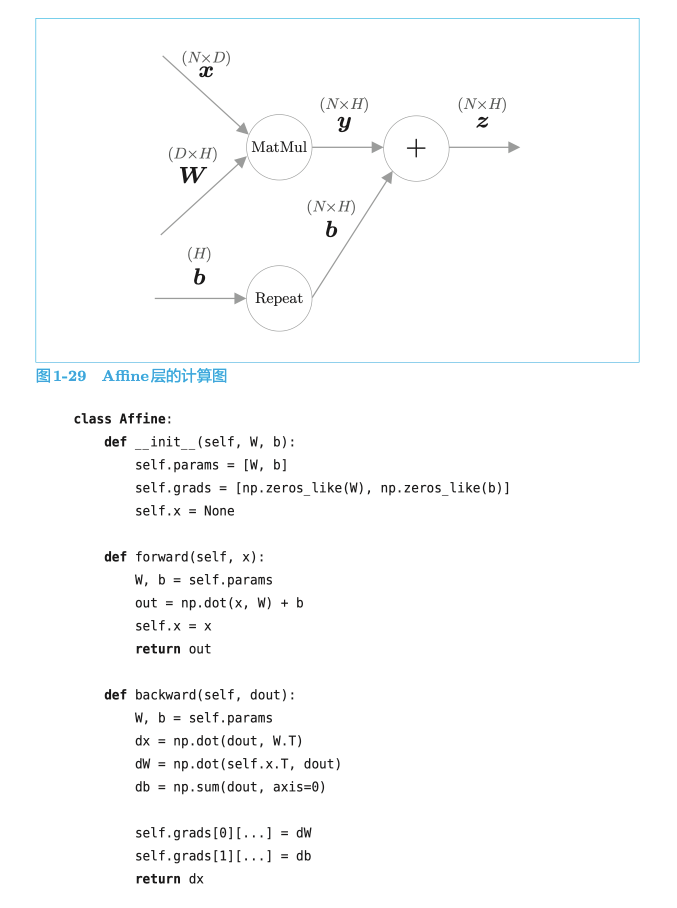
1.4.1 Softmax with Loss 层
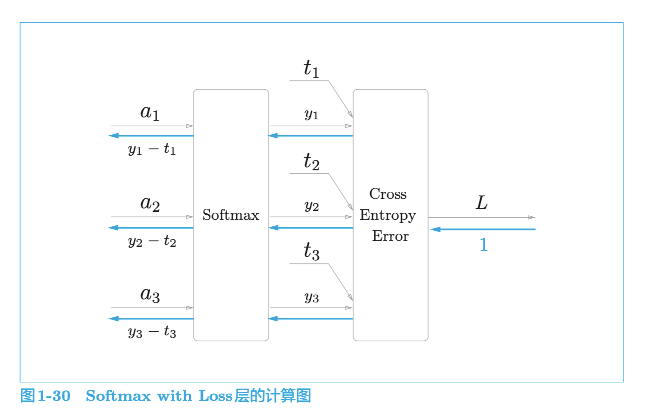
1 | # Softmax with Loss |
1.5 梯度下降
随机梯度下降法
梯度下降:在训练过程中,反向传播将不断更新权重的梯度,让损失不断降低

首先,选择 mini-batch 数据,根据误差反向传播法获得权重的梯度。这个梯度指向当前的权重参数所处位置中损失增加最多的方向。因此,通过将参数向该梯度的反方向更新,可以降低损失。这就是梯度下降法
权重更新方法:
随机梯度下降法 SGD
- “随机”是指使用随机选择的数据(mini-batch)的梯度。
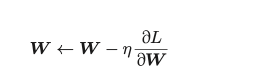
η 表示学习率
- “随机”是指使用随机选择的数据(mini-batch)的梯度。
批量梯度下降算法BGD
小批量 梯度下降算法MBGD
1.6 单层感知机
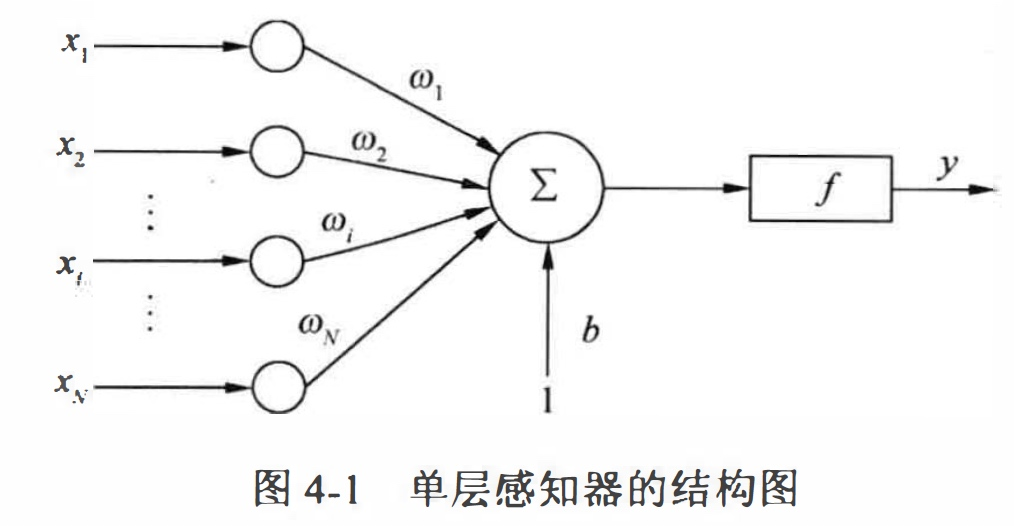
单层感知器属于单层前向网络,即除输入层和输出层之外,只拥有一层神经元节点。前向网络的特点是,输入数据从输入层经过隐藏层向输出层逐层传播,相邻两层的神经元之间相互连接, 同一层的神经元之间则没有连接。
2 自然语言处理
要想让计算机理解自然语言的前提就是让其理解每个单词的含义。我们主要有3种方法实现:
- 基于同义词词典的方法
- WordNet
- 基于计数的方法
- 基于推理的方法(word2vec)
单词的分布式表示
我们能不能将类似于颜色RGB表示方法运用到单词上呢?在单词领域构建紧凑合理的向量表示,在自然语言处理领域,这称为分布式表示。单词的分布式表示将单词表示为固定长度的向量。这种向量的特征在于它是用密集向量表示的。
密集向量:向量的各个元素(大多数)是由非 0 实数表示的。例如三维分布式表示是$[0.21,-0.45,0.83]$
分布式假设:“某个单词的含义由它周围的单词形成”,称为分布式假设。
2.2 基于计数的方法
基于计数的方法根据一个单词周围的单词的出现频数来表示该单词。具体来说,先生成所有单词的共现矩阵,再对这个矩阵进行SVD,以获得密集向量(单词的分布式表示)。但是,基于计数的方法在处理大规模语料库时会出现问题。
奇异值分解(Singular Value Decomposition,SVD)是矩阵分解的一种方法,将一个矩阵分解为三个矩阵的乘积:$M = U \Sigma V^T$,其中 $U$ 和 $V$是正交矩阵,$\Sigma$是对角矩阵,包含奇异值。
通过SVD,可以将原始高维稀疏矩阵压缩为低维稠密矩阵。这些低维矩阵的行向量或列向量就可以作为单词的向量表示。
SVD的作用:降维、去噪、稠密表示等
缺点:计算量太大导致计算机难以处理
语料库的预处理
现在,我们对一个非常小的文本数据(语料库)进行预处理。这里所说的预处理是指:
- 将文本分割成单词
- 单词列表转化为单词ID列表
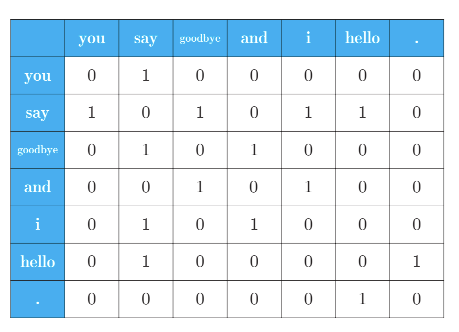
2.2.2 共现矩阵
用表格表示单词的上下文中包含的单词的频数,作为单词的向量表示

对一个句子中所有的单词进行处理,就可以得到如下的共现矩阵:
2.2.3 余弦相似度(cosine similarity)
在测量单词的向量表示的相似度方面,余弦相似度是很常用的。
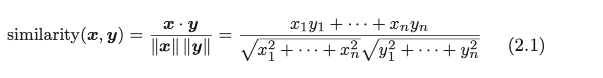
2.2.4 点互信息
共现矩阵的元素表示两个单词同时出现的次数。但是,这种“原始”的次数并不具备好的性质。
比如“the car…”这样的短语,它们的共现次数将会很大。另外,car 和 drive 也明显有很强的相关性。但是,如果只看单词的出现次数,那么与 drive 相比,the 和 car 的相关性更强。这意味着,仅仅因为 the 是个常用词,它就被认为与 car 有很强的相关性,这显然不是我们想要的。
点互信息被用于解决这一问题:
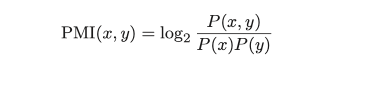
其中,P(x) 表示 x 发生的概率,P(y) 表示 y 发生的概率,P(x, y) 表示 x 和 y 同时发生的概率。PMI 的值越高,表明相关性越强。
2.2.4.1 正的点互信息
解决当两个单词的共现次数为 0 时,log20 = −∞。
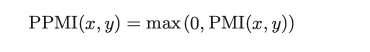
尽管PPMI矩阵能够改善之前共现矩阵存在的高频词汇问题,但是这两种方法都存在一个共性问题:随着单词数目的增加,矩阵的维数也在增加,而其中很多元素都为0(不重要的元素);向量容易受到噪声的影响,稳定性差。
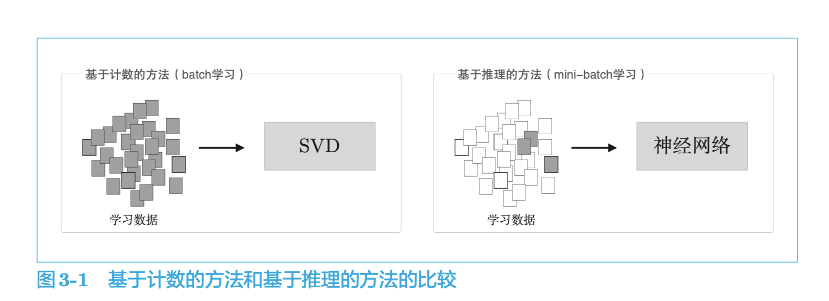
基于计数的方法使用整个语料库的统计数据(共现矩阵和 PPMI 等 ),通过一次处理(SVD 等)获得单词的分布式表示。而基于推理的方法使用神经网络,通常在 mini-batch 数据上进行学习。这意味着神经网络一次只需要看一部分学习数据(mini-batch),并反复更新权重。这种学习机制上的差异如图 3-1 所示。
2.3 基于推理的方法
基于推理的方法的主要操作是“推理”。当给出周围的单词(上下文)时,预测“?”处会出现什么单词,这就是推理。

2.3.1 word2vec
word2vec 一词最初用来指程序或者工具,但是随着该词的流行,在某些语境下,也指神经网络的模型。
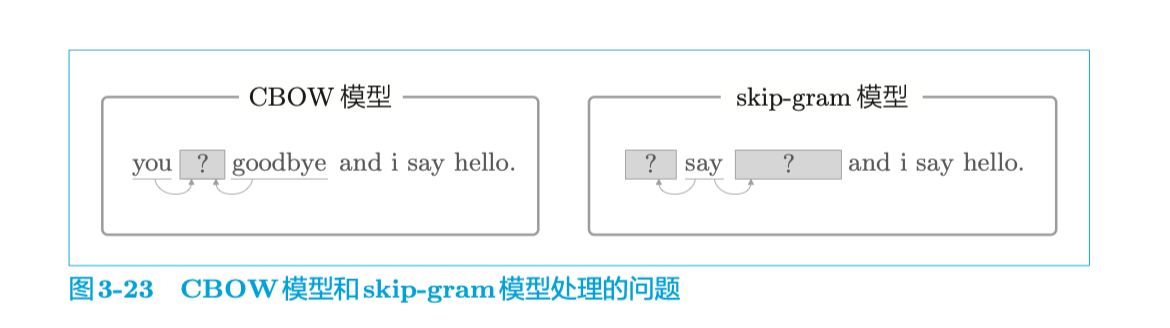
word2vec 中使用的两个神经网络分别是CBOW 模型和 skip-gram 模型
2.3.1.1 CBOW 模型
continuous bag-of-words(CBOW)连续词袋模型
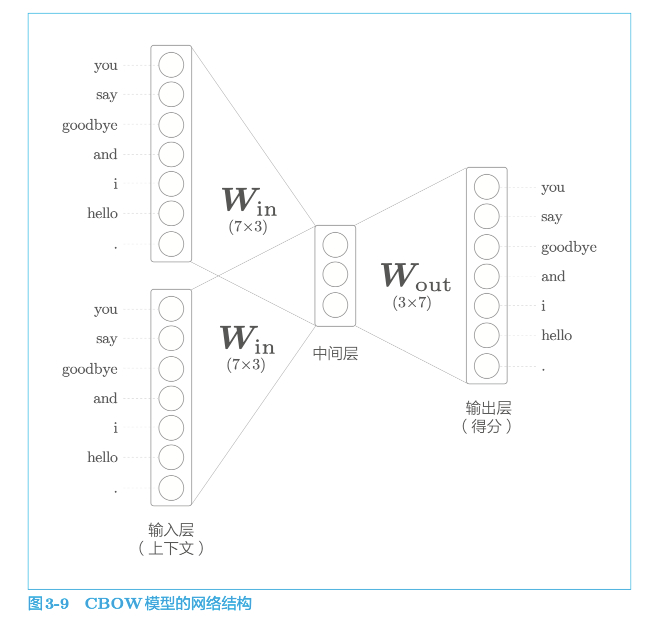
中间层的神经元数量比输入层少这一点很重要。中间层需要将预测单词所需的信息压缩保存,从而产生密集的向量表示。这时,中间层被写入了我们人类无法解读的代码,这相当于“编码”工作。而从中间层的信息获得期望结果的过程则称为“解码”。这一过程将被编码的信息复原为我们可以理解的形式。
2.3.1.1.1 CBOW模型的学习


CBOW模型只是学习语料库中单词的出现模式。如果语料库不一样,学习到的单词的分布式表示也不一样。比如,只使用“体育”相关的文章得到的单词的分布式表示,和只使用“音乐”相关的文章得到的单词的分布式表示将有很大不同。
2.3.1.1.2 CBOW损失函数
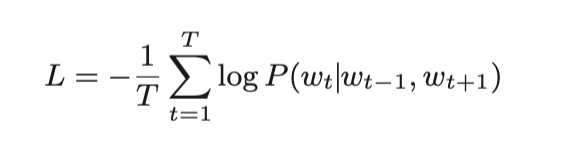
CBOW 模型学习的任务就是让损失函数尽可能地小。那时的权重参数就是我们想要的单词的分布式表示。
2.3.1.2 word2vec的权重和分布式表示
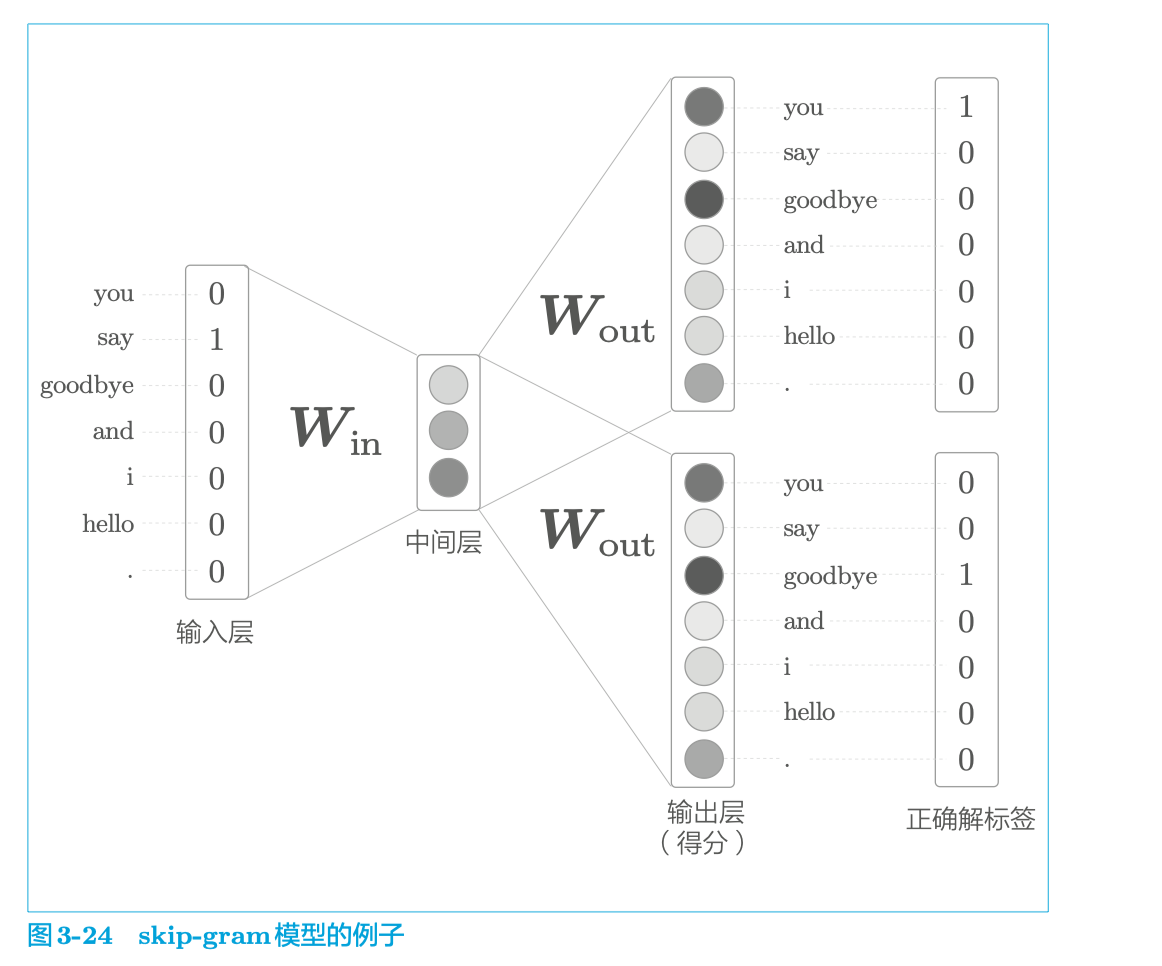
word2vec 中使用的网络有两个权重,分别是输入侧的全连接层的权重($W_{in} $)和输出侧的全连接层的权重($W_{out} $)。
就 word2vec(特别是 skip-gram 模型)而言,最受欢迎的是只使用输入侧的权重。
2.3.2 skip-gram模型
skip-gram 是反转了 CBOW 模型处理的上下文和目标词的模型。
3 word2vec的高速化
TODO
4 RNN
前馈神经网络FNN:最简单的网络,各神经元分层排列,每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层,各层间没有反馈
到目前为止,我们看到的神经网络都是前馈型神经网络。虽然前馈网络结构简单、易于理解,但是可以应用于许多任务中。不过,这种网络存在一个大问题,就是不能很好地处理时间序列数据。更确切地说,单纯的前馈网络无法充分学习时序数据的性质。于是,RNN(Recurrent Neural Network,循环神经网络)便应运而生。
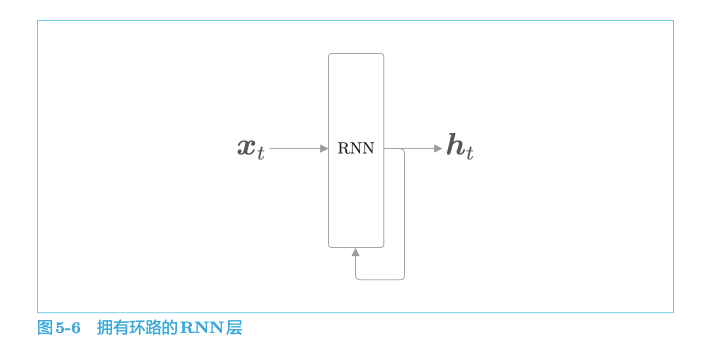
RNN 的特征就在于拥有这样一个环路。这个环路可以使数据不断循环。通过数据的循环,RNN 一边记住过去的数据,一边更新到最新的数据。

RNN 有两个权重,分别是将输入 x 转化为输出 h 的权重$ W_{x} $和将前一个 RNN 层的输出转化为当前时刻的输出的权重 $W_{h}$。

$$
\boldsymbol{h}{t}=\tanh \left(\boldsymbol{h}{t-1} \boldsymbol{W}{h}+\boldsymbol{x}{t} \boldsymbol{W}_{x}+\boldsymbol{b}\right)
$$
从另一个角度看,这可以解释为,RNN 具有“状态”$h$,并以上式的形式被更新。这就是说RNN层是“具有状态的层”或“具有存储(记忆)的层”的原因。RNN 的输出 $h_{t}$称为隐藏状态或隐藏状态向量
RNN有两个权重:$W_{h}$和$W_{x}$
4.1 Backpropagation Through Time
RNN的误差反向传播法是“按时间顺序展开的神经网络的误差反向传播法”,所以称为 Backpropagation Through Time(基于时间的反向传播),简称 BPTT。
4.1.1 Truncated BPTT
在处理长时序数据时,通常的做法是将网络连接截成适当的长度。具体来说,就是将时间轴方向上过长的网络在合适的位置进行截断,从而创建多个小型网络,然后对截出来的小型网络执行误差反向传播法,这个方法称为 Truncated BPTT(截断的 BPTT)。
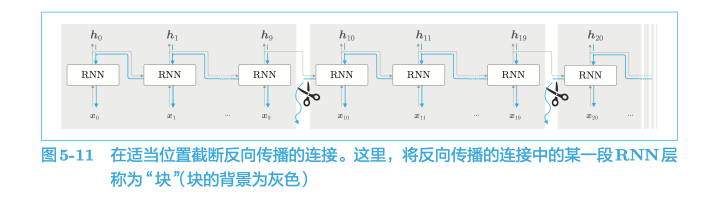
这里需要注意的是,虽然反向传播的连接会被截断,但是正向传播的连接不会。
4.2 RNN反向传播


4.3 RNNLM
基于 RNN 的语言模型称为 RNNLM(RNN Language Model,RNN 语言模型)
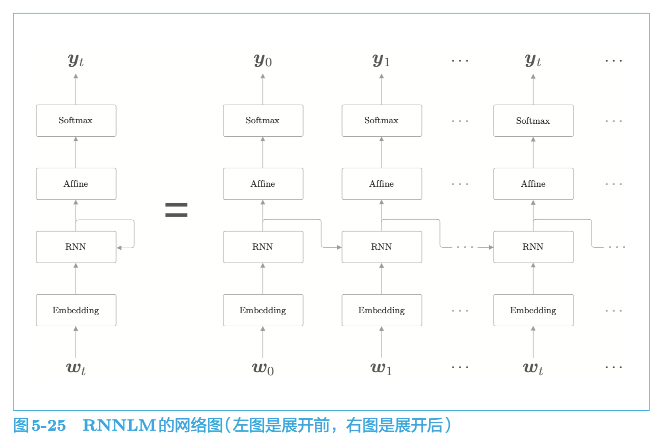

Embedding 层:将单词 ID 转化为单词的分布式表示(单词向量)
4.3.1 梯度消失和梯度爆炸
RNN 层通过向过去传递“有意义的梯度”,能够学习时间方向上的依赖关系。此时梯度(理论上)包含了那些应该学到的有意义的信息,通过将这些信息向过去传递,RNN 层学习长期的依赖关系。但是,如果这个梯度在中途变弱(甚至没有包含任何信息),则权重参数将不会被更新。也就是说,RNN 层无法学习长期的依赖关系。不幸的是,随着时间的回溯,这个简单 RNN 未能避免梯度变小(梯度消失)或者梯度变大(梯度爆炸)的命运。
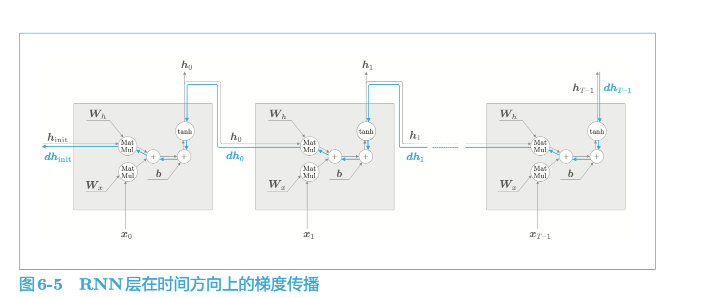
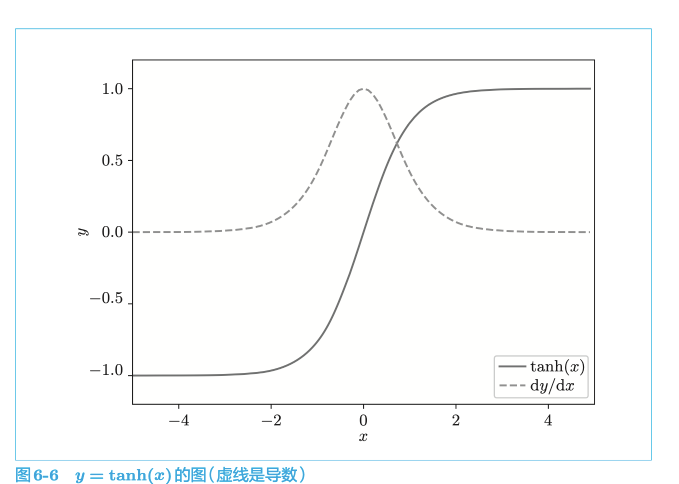
当反向传播的梯度经过tanh 节点时,它的值会越来越小。因此,如果经过 tanh 函数 T 次,则梯度也会减小 T 次。
RNN 层的激活函数一般使用 tanh 函数,但是如果改为 ReLU 函数,则有希望抑制梯度消失的问题(当 ReLU 的输入为 x 时,它的输出是max(0, x))。这是因为,在 ReLU 的情况下,当 x 大于 0 时,反向传播将上游的梯度原样传递到下游,梯度不会“退化”。
4.4 Gated RNN
上文提到的RNN 不擅长学习时序数据的长期依赖关系,原因是 BPTT 会发生梯度消失和梯度爆炸的问题。
当我们说 RNN 时,更多的是指 LSTM 层,而不是上一章的 RNN。
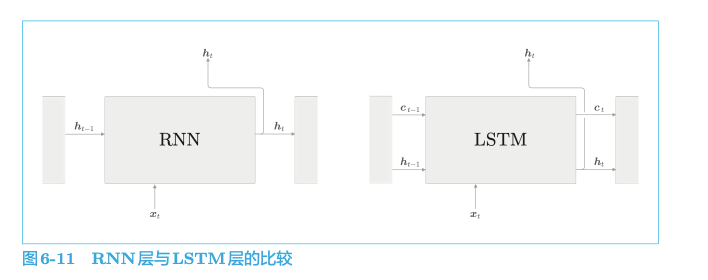
LSTM 与 RNN 的接口的不同之处在于,LSTM 还有路径 c。这个 c 称为记忆单元(或者简称为“单元”),相当于 LSTM 专用的记忆部门。
记忆单元的特点是,仅在 LSTM 层内部接收和传递数据。也就是说,记忆单元在 LSTM 层内部结束工作,不向其他层输出。而 LSTM 的隐藏状态 h 和 RNN 层相同,会被(向上)输出到其他层。
4.5 LSTM
4.5.1 输出门
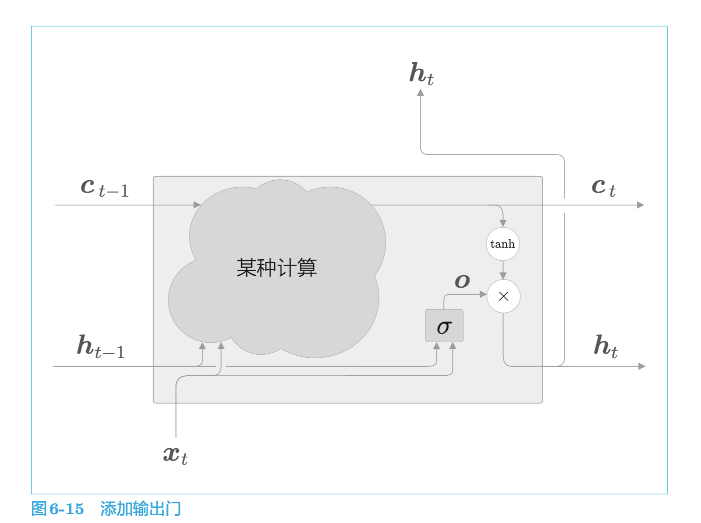

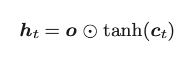
sigmoid 函数用 $σ()$ 表示
tanh的输出是−1.0 ~ 1.0的实数。我们可以认为这个−1.0 ~ 1.0的数值表示某种被编码的“信息”的强弱(程度)。而sigmoid 函数的输出是0.0~1.0的实数,表示数据流出的比例。因此,在大多数情况下,门使用sigmoid函数作为激活函数,而包含实质信息的数据则使用tanh函数作为激活函数。
4.5.2 遗忘门
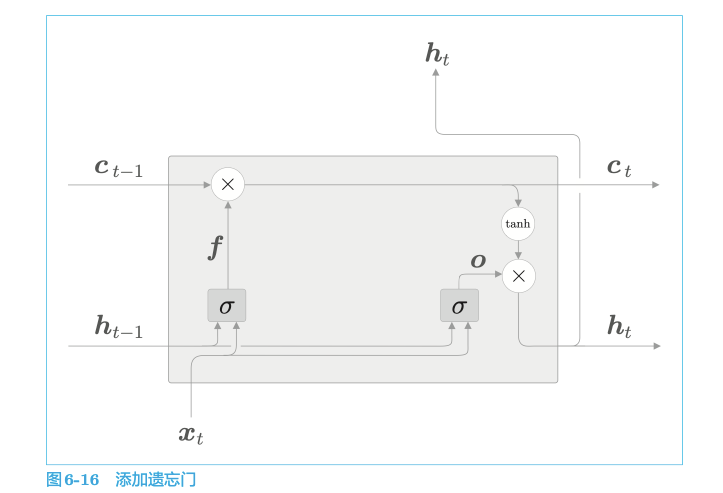
4.5.3 新的记忆单元

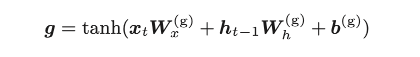
4.5.4 输入门
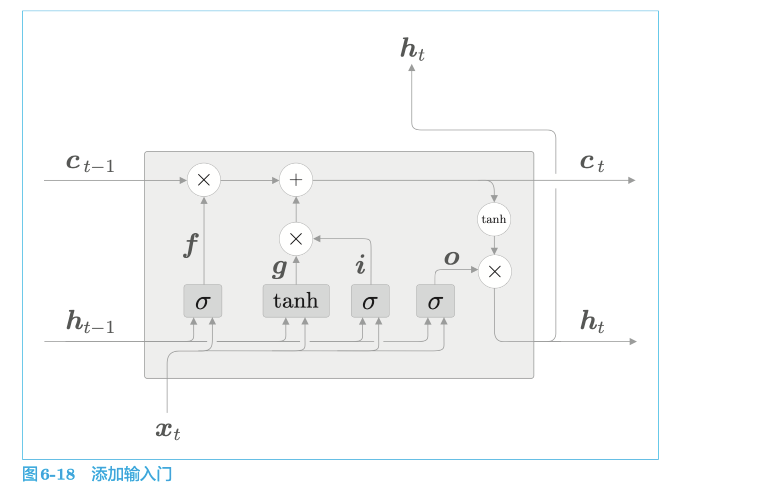
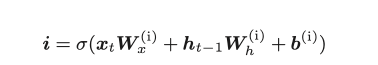
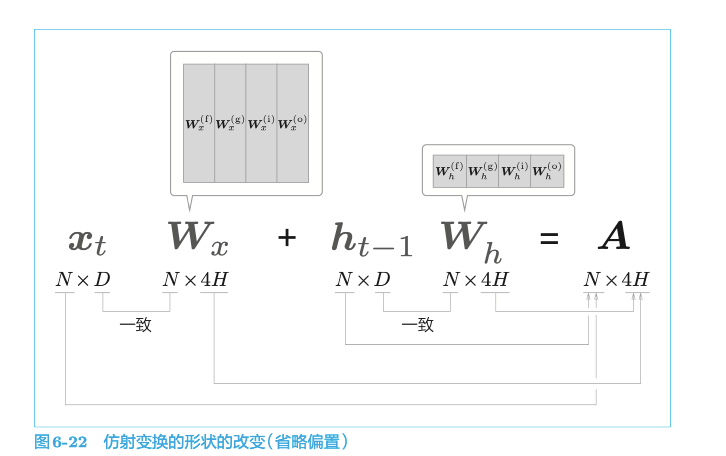
4.5.5 LSTM的实现
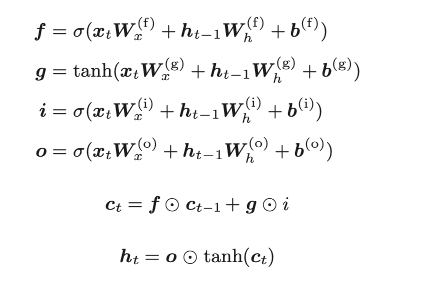
简化后:
5 Attention
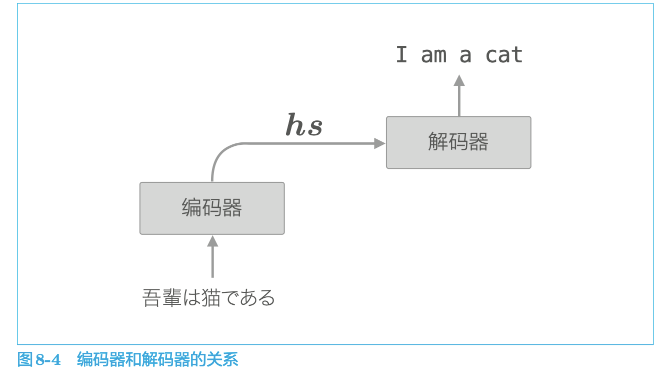
5.1 seq2seq改进
seq2seq存在的问题:无论输入语句多长,编码器都将其塞入固定长度的向量中,有用的信息也会从向量中溢出。
5.1.1 编码器优化
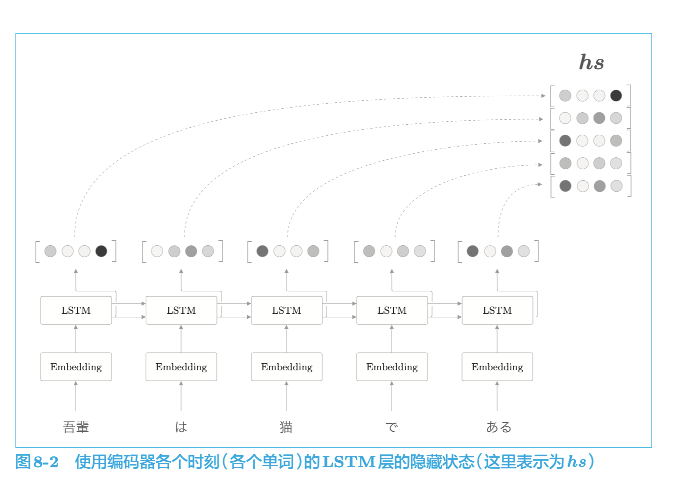
使用各个时刻(各个单词)的隐藏状态向量,可以获得和输入的单词数相同数量的向量。
编码器输出的 $h_{s}$ 矩阵就可以视为各个单词对应的向量集合。
这样一来,编码器就摆脱了“一个固定长度的向量”的制约。
5.1.2 解码器的改进
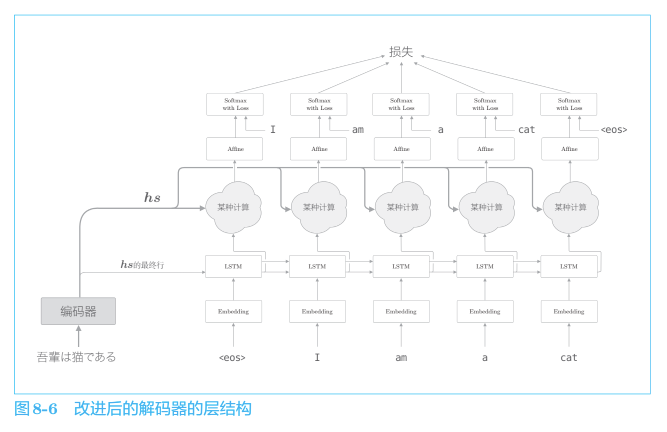
网络所做的工作是提取单词对齐信息。具体来说,就是从 $h_{s}$ 中选出与各个时刻解码器输出的单词有对应关系的单词向量。但是“选择”这一操作是不可微分的,这里使用了单词重要度的权重$a$,计算$a$和$h_{s}$ 加权和可以获得目标向量:
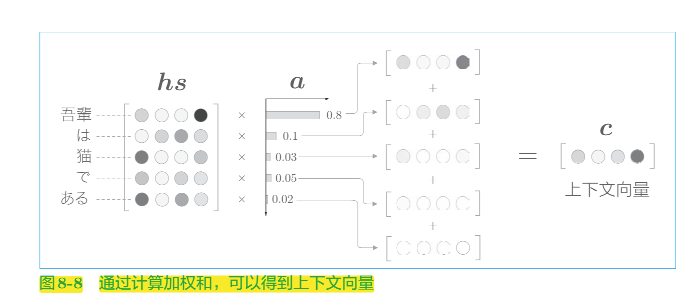
上下文向量 c 中包含了当前时刻进行变换(翻译)所需的信息。更确切地说,模型要从数据中学习出这种能力。
如何获取$a$?
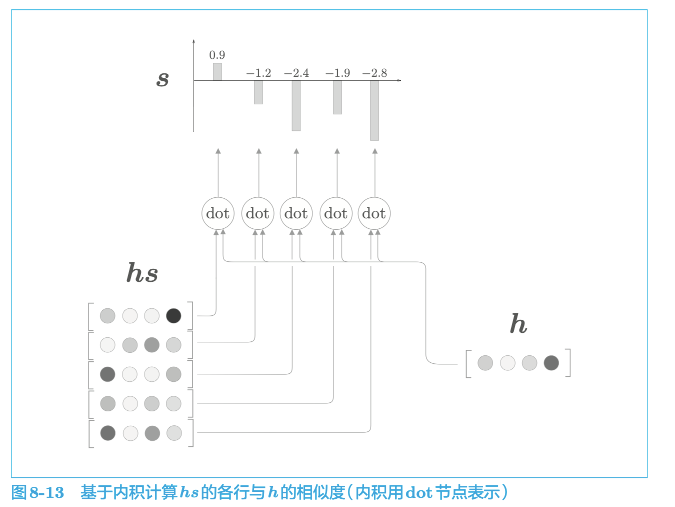
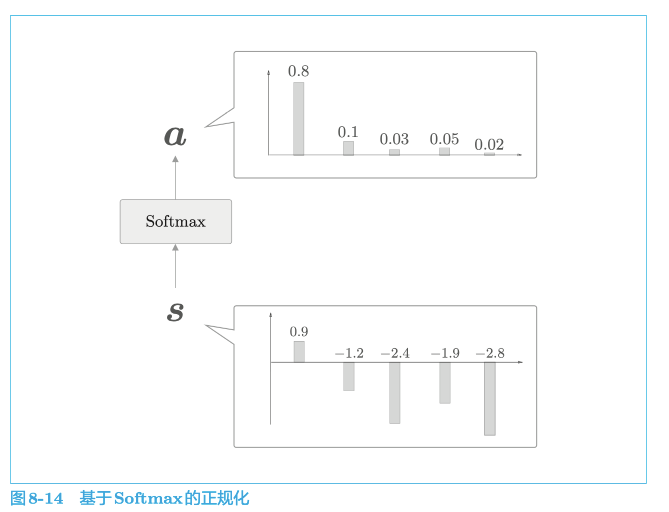
$h$ 表示解码器的 LSTM 层的隐藏状态向量,用$h$和$h_{s}$的内积表示这个 h 在多大程度上和 hs 的各个单词向量“相似”,并将其结果表示为 s,正则化后就得到了a
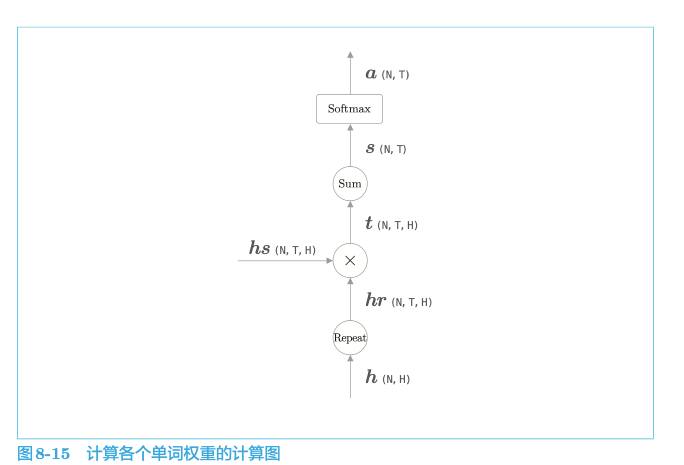
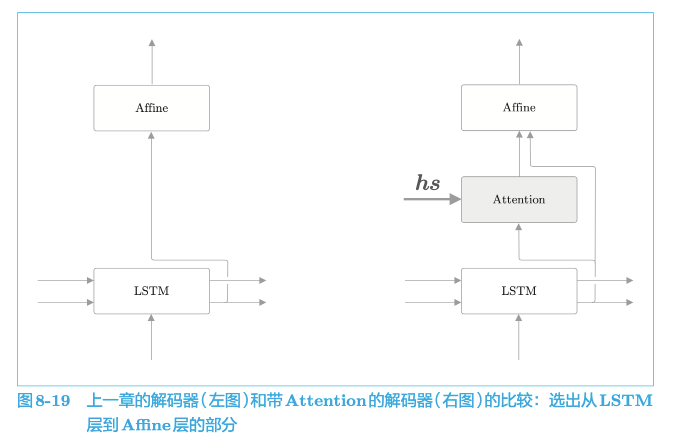
5.1.3 Attention结构
总结:
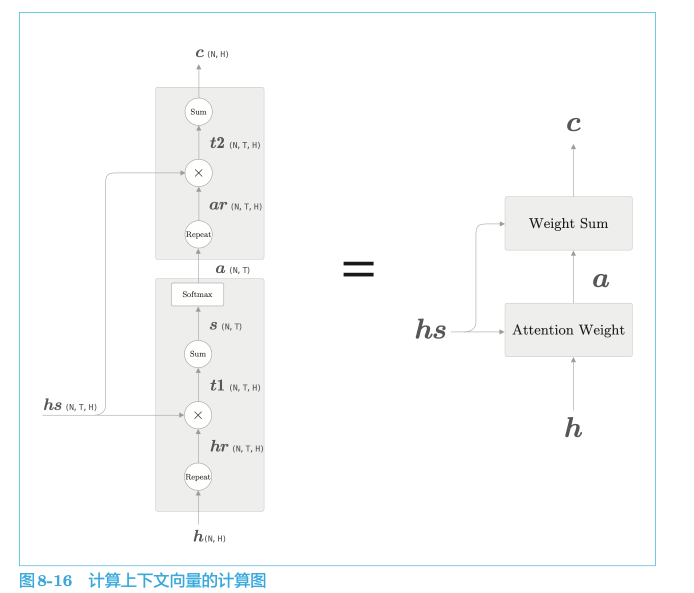
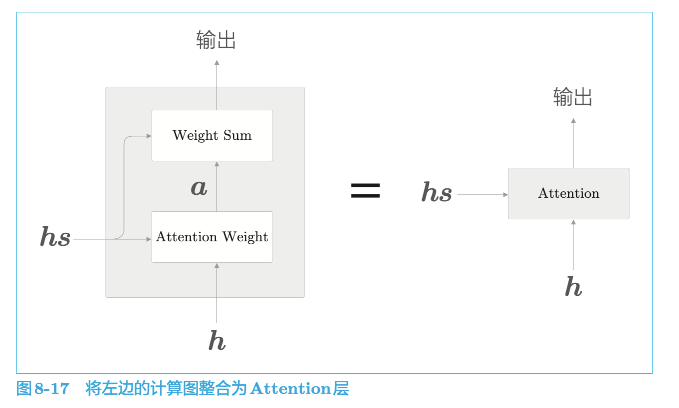
我们上面对seq2seq的优化实际就是加了一层Attention层: