环境搭建
- GOPATH:代表 Go 语言项目的工作目录,在 Go Module 模式之前非常重要,现在基本上用来存放使用 go get 命令获取的项目。
- GOBIN:代表 Go 编译生成的程序的安装目录,比如通过 go install 命令,会把生成的 Go 程序安装到 GOBIN 目录下,以供你在终端使用。
- Go代理:
GOPROXY=https://goproxy.cn
1 | export GOROOT=/usr/local/go |
编译发布
go build编译生成可执行文件
go install把它安装到 $GOBIN 目录或者任意位置
跨平台编译
Go 语言通过两个环境变量来控制跨平台编译,它们分别是 GOOS 和 GOARCH 。
- GOOS:代表要编译的目标操作系统,常见的有 Linux、Windows、Darwin 等。
- GOARCH:代表要编译的目标处理器架构,常见的有 386、AMD64、ARM64 等。
1 | GOOS=linux GOARCH=amd64 go build ./ch01/main.go |
基本数据类型
整型
- 有符号整型:如
int、int8、int16、int32和int64。 - 无符号整型:如
uint、uint8、uint16、uint32和uint64。
除了有用“位”(bit)大小表示的整型外,还有 int 和 uint 这两个没有具体 bit 大小的整型,它们的大小可能是 32bit,也可能是 64bit,和硬件设备 CPU 有关。
浮点数
float32float64
复数
complex64complex128
复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位
布尔值
bool
- 布尔类型变量的默认值为false。
- Go 语言中不允许将整型强制转换为布尔型.
- 布尔型无法参与数值运算,也无法与其他类型进行转换
字符串
*** Go 语言里的字符串的内部实现使用UTF-8编码,每个字符串的底层都是byte数组***
- byte:相当于uint8
- rune:相当于int32
- Go 使用了特殊
rune类型来处理Unicode(复合字符,包括中文、日文等用多字节表示字符)
- Go 使用了特殊
1 | //utf-8遍历 |
Array、Slice、Map
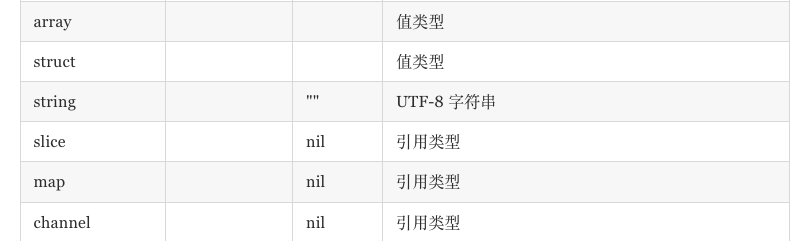
1 | array1:=[5]string{1:"b",3:"d"} |
📌提示
在创建新切片的时候,最好要让新切片的长度和容量一样,这样在追加操作的时候就会生成新的底层数组,从而和原有数组分离,就不会因为共用底层数组导致修改内容的时候影响多个切片。
函数和方法
在 Go 语言中,方法和函数是两个概念,但又非常相似,不同点在于方法必须要有一个接收者,这个接收者是一个类型,这样方法就和这个类型绑定在一起,称为这个类型的方法。
- 函数:正常的代码逻辑
- 方法:特定类型才有,相当于对象的方法
值类型接收者和指针类型接收者
- 值类型接收者:不会改变原来的对象,相当于操作对象的拷贝
- 指针类型接收者:通过指针可以获取对象地址,可以直接改变原来的对象
提示:在调用方法的时候,传递的接收者本质上都是副本,只不过一个是这个值的副本,一是指向这个值指针的副本。指针具有指向原有值的特性,所以修改了指针指向的值,也就修改了原有的值。我们可以简单地理解为值接收者使用的是值的副本来调用方法,而指针接收者使用实际的值来调用方法。
📌值接受者方法不会改变原始结构体实例
- 如果使用一个值类型变量调用指针类型接收者的方法,Go 语言编译器会自动帮我们取指针调用,以满足指针接收者的要求。
- 同样的原理,如果使用一个指针类型变量调用值类型接收者的方法,Go 语言编译器会自动帮我们解引用调用,以满足值类型接收者的要求。
值类型调用者和指针类型调用者
在官方effective go文档中,对两者区别描述如下:
- 值方法(value methods)可以通过指针和值调用,但是指针方法(pointer methods)只能通过指针来调用。
- 但有一个例外,如果某个值是可寻址的(addressable,或者说左值),那么编译器会在值调用指针方法时自动插入取地址符,使得在此情形下看起来像指针方法也可以通过值来调用。
总结:
- 不管是普通对象还是指针,都可以调用他们的值方法和指针方法,因为编译器会自行处理(语法糖
- 遇事不决请用pointer method!!!
通过变量调用方法
1 | student := Student("my name is xiaoming, I am ") |
结构体和接口
结构体定义:
1 | type Stu struct{ |
以指针类型接收者实现接口的时候,只有对应的指针类型实例才被认为实现了该接口。
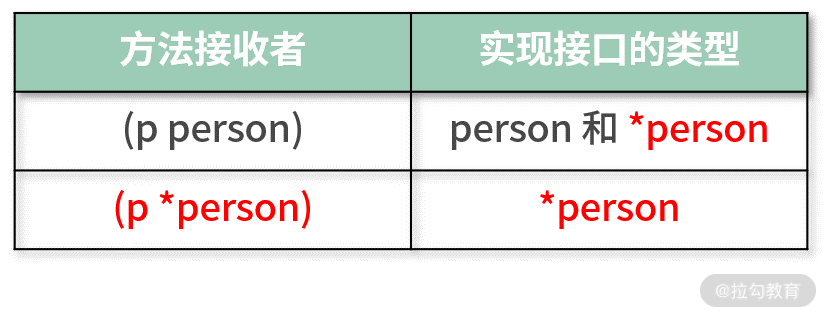
工厂函数(构造函数)
工厂函数一般用于创建自定义的结构体,便于使用者调用
1 | func NewPerson(name string) *person { |
继承和组合
在 Go 语言中没有继承的概念,所以结构、接口之间也没有父子关系,Go 语言提倡的是组合,利用组合达到代码复用的目的,这也更灵活。
1 | // 组合 |
类型组合后,外部类型不仅可以使用内部类型的字段,也可以使用内部类型的方法,就像使用自己的方法一样。
方法覆写:如果外部类型定义了和内部类型同样的方法,那么外部类型的会覆盖内部类型,这就是。
类型断言
类型断言用来判断一个接口的值是否是实现该接口的某个具体类型。
接口引用拥有断言能力,用于判断当前引用是否属于某个对象的实例
1 | // 接口引用指向子类实例 |
在类型断言的时候,同时完成了类型转换
Error
在 Go 语言中,错误是通过内置的 error 接口表示的:
1 | // error 定义 |
自定义异常
1 | type commonError struct { |
Error Wrapping
上述自定义异常可以满足我们的需求,但是非常烦琐,因为既要定义新的类型还要实现 error 接口。
Go 语言 1.13 版本开始,Go 标准库新增了 Error Wrapping 功能,让我们可以基于一个存在的 error 生成新的 error,并且可以保留原 error 信息。
1 | // wrap |
errors.Is
有了 Error Wrapping 后,你会发现原来用的判断两个 error 是不是同一个 error 的方法失效了,比如 Go 语言标准库经常用到的如下代码中的方式:
1 | fmt.Println(errors.Is(w, e)) // true |
errors.ls
1 | func Is(err, target error) bool |
以上就是errors.Is 函数的定义,可以解释为:
- 如果 err 和 target 是同一个,那么返回 true。
- 如果 err 是一个 wrapping error,target 也包含在这个嵌套 error 链中的话,也返回 true。
📌可以简单地概括为,两个 error 相等或 err 包含 target 的情况下返回 true,其余返回 false。
errors.As
同样的原因,有了 error 嵌套后,error 断言也不能用了,因为你不知道一个 error 是否被嵌套,又嵌套了几层。所以 Go 语言为解决这个问题提供了 errors.As 函数,比如前面 error 断言的例子,可以使用 errors.As 函数重写,效果是一样的,如下面的代码所示:
1 | var cm *commonError |
Deferred
defer 语句常被用于成对的操作,如文件的打开和关闭,加锁和释放锁,连接的建立和断开等。不管多么复杂的操作,都可以保证资源被正确地释放。
1 | func ReadFile(filename string) ([]byte, error) { |
- 在一个方法或者函数中,可以有多个 defer 语句;
- defer 有一个调用栈,多个 defer 语句的执行顺序依照后进先出的原则。
Panic
Go 语言是一门静态的强类型语言,很多问题都尽可能地在编译时捕获,但是有一些只能在运行时检查,比如数组越界访问、不相同的类型强制转换等,这类运行时的问题会引起 panic 异常。除了运行时可以产生 panic 外,我们自己也可以抛出 panic 异常。
1 | func panic(v interface{}) |
interface{}是空接口的意思,在 Go 语言中代表任意类型。
panic 异常是一种非常严重的情况,会让程序中断运行,使程序崩溃,所以如果是不影响程序运行的错误,不要使用 panic,使用普通错误 error 即可。
Recover 捕获 Panic 异常
通常情况下,我们不对 panic 异常做任何处理,因为既然它是影响程序运行的异常,就让它直接崩溃即可。但是也的确有一些特例,比如在****程序崩溃前做一些资源释放的处理,这时候就需要从 panic 异常中恢复,才能完成处理。
1 | func connectMySQL(ip, username, password string) { |
并发基础
协程(Goroutine)
Go 语言中没有线程的概念,只有协程,也称为 goroutine。
1 | go function() |
Channel
1 | ch:=make(chan string) |
- 接收:获取 chan 中的值,操作符为
<- chan。 - 发送:向 chan 发送值,把值放在 chan 中,操作符为
chan <-。
无缓冲 channel
无缓冲 channel,它的容量是 0,不能存储任何数据。所以无缓冲 channel 只起到传输数据的作用,数据并不会在 channel 中做任何停留。这也意味着,无缓冲 channel 的发送和接收操作是同时进行的,它也可以称为同步 channel。
有缓冲 channel
有缓冲 channel 类似一个可阻塞的队列,内部的元素先进先出。通过 make 函数的第二个参数可以指定 channel 容量的大小,进而创建一个有缓冲 channel。
1 | cacheCh:=make(chan int,5) |
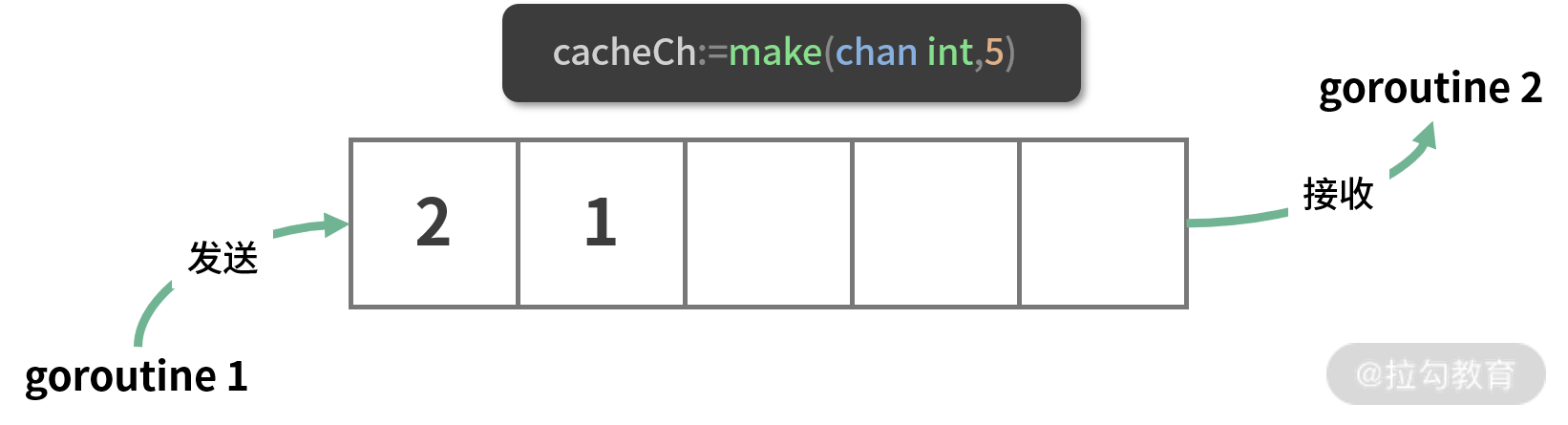
一个有缓冲 channel 具备以下特点:
- 有缓冲 channel 的内部有一个缓冲队列;
- 发送操作是向队列的尾部插入元素,如果队列已满,则阻塞等待,直到另一个 goroutine 执行,接收操作释放队列的空间;
- 接收操作是从队列的头部获取元素并把它从队列中删除,如果队列为空,则阻塞等待,直到另一个 goroutine 执行,发送操作插入新的元素。
1 | // 获取队列容量和元素个数: |
如果一个 channel 被关闭了,就不能向里面发送数据了,如果发送的话,会引起 painc 异常。但是还可以接收 channel 里的数据,如果 channel 里没有数据的话,接收的数据是元素类型的零值。
单向 channel
有时候,我们有一些特殊的业务需求,比如限制一个 channel 只可以接收但是不能发送,或者限制一个 channel 只能发送但不能接收,这种 channel 称为单向 channel。
1 | onlySend := make(chan<- int) |
select 多路复用
小提示:多路复用可以简单地理解为,N 个 channel 中,任意一个 channel 有数据产生,select 都可以监听到,然后执行相应的分支,接收数据并处理。
1 | select { |
sync 包
小技巧:使用 go build、go run、go test 这些 Go 语言工具链提供的命令时,添加
-race标识可以帮你检查 Go 语言代码是否存在资源竞争。
sync.Mutex
互斥锁,顾名思义,指的是在同一时刻只有一个协程执行某段代码,其他协程都要等待该协程执行完毕后才能继续执行。
Mutex 的 Lock 和 Unlock 方法总是成对出现,而且要确保 Lock 获得锁后,一定执行 UnLock 释放锁
1 | var( |
小提示:以上被加锁保护的 sum+=i 代码片段又称为临界区。在同步的程序设计中,临界区段指的是一个访问共享资源的程序片段,而这些共享资源又有无法同时被多个协程访问的特性。
sync.RWMutex
go中的读写锁。使用:
1 | var mutex sync.RWMutex |
sync.WaitGroup
相当于Java中的***CountDownLatch***,用于最终完成的场景,关键点在于一定要等待所有协程都执行完毕。
1 | func run(){ |
sync.Once
让代码只执行一次,哪怕是在高并发的情况下,比如创建一个单例。
1 | func main() { |
sync.Cond
sync.Cond 可以用于发号施令,一声令下所有协程都可以开始执行,关键点在于协程开始的时候是等待的,要等待 sync.Cond 唤醒才能执行。
1 | //10个人赛跑,1个裁判发号施令 |
- Wait,阻塞当前协程,直到被其他协程调用 Broadcast 或者 Signal 方法唤醒,使用的时候需要加锁,使用 sync.Cond 中的锁即可,也就是 L 字段。
- Signal,唤醒一个等待时间最长的协程。
- Broadcast,唤醒所有等待的协程。
注意:在调用 Signal 或者 Broadcast 之前,要确保目标协程处于 Wait 阻塞状态,不然会出现死锁问题。
如果你以前学过 Java,会发现 sync.Cond 和 Java 的等待唤醒机制很像,它的三个方法 Wait、Signal、Broadcast 就分别对应 Java 中的 wait、notify、notifyAll。
Context
一个任务会有很多个协程协作完成,一次 HTTP 请求也会触发很多个协程的启动,而这些协程有可能会启动更多的子协程,并且无法预知有多少层协程、每一层有多少个协程。
如果因为某些原因导致任务终止了,HTTP 请求取消了,那么它们启动的协程怎么办?该如何取消呢?因为取消这些协程可以节约内存,提升性能,同时避免不可预料的 Bug。
Context 就是用来简化解决这些问题的,并且是并发安全的。Context 是一个接口,它具备手动、定时、超时发出取消信号、传值等功能,主要用于控制多个协程之间的协作,尤其是取消操作。一旦取消指令下达,那么被 Context 跟踪的这些协程都会收到取消信号,就可以做清理和退出操作。
1 | type Context interface { |
Context 树
Go 语言提供了函数可以帮助我们生成不同的 Context,通过这些函数可以生成一颗 Context 树,这样 Context 才可以关联起来,父 Context 发出取消信号的时候,子 Context 也会发出,这样就可以控制不同层级的协程退出。
从使用功能上分,有四种实现好的 Context。
- 空 Context:不可取消,没有截止时间,主要用于 Context 树的根节点。
- 可取消的 Context:用于发出取消信号,当取消的时候,它的子 Context 也会取消。
- 可定时取消的 Context:多了一个定时的功能。
- 值 Context:用于存储一个 key-value 键值对。
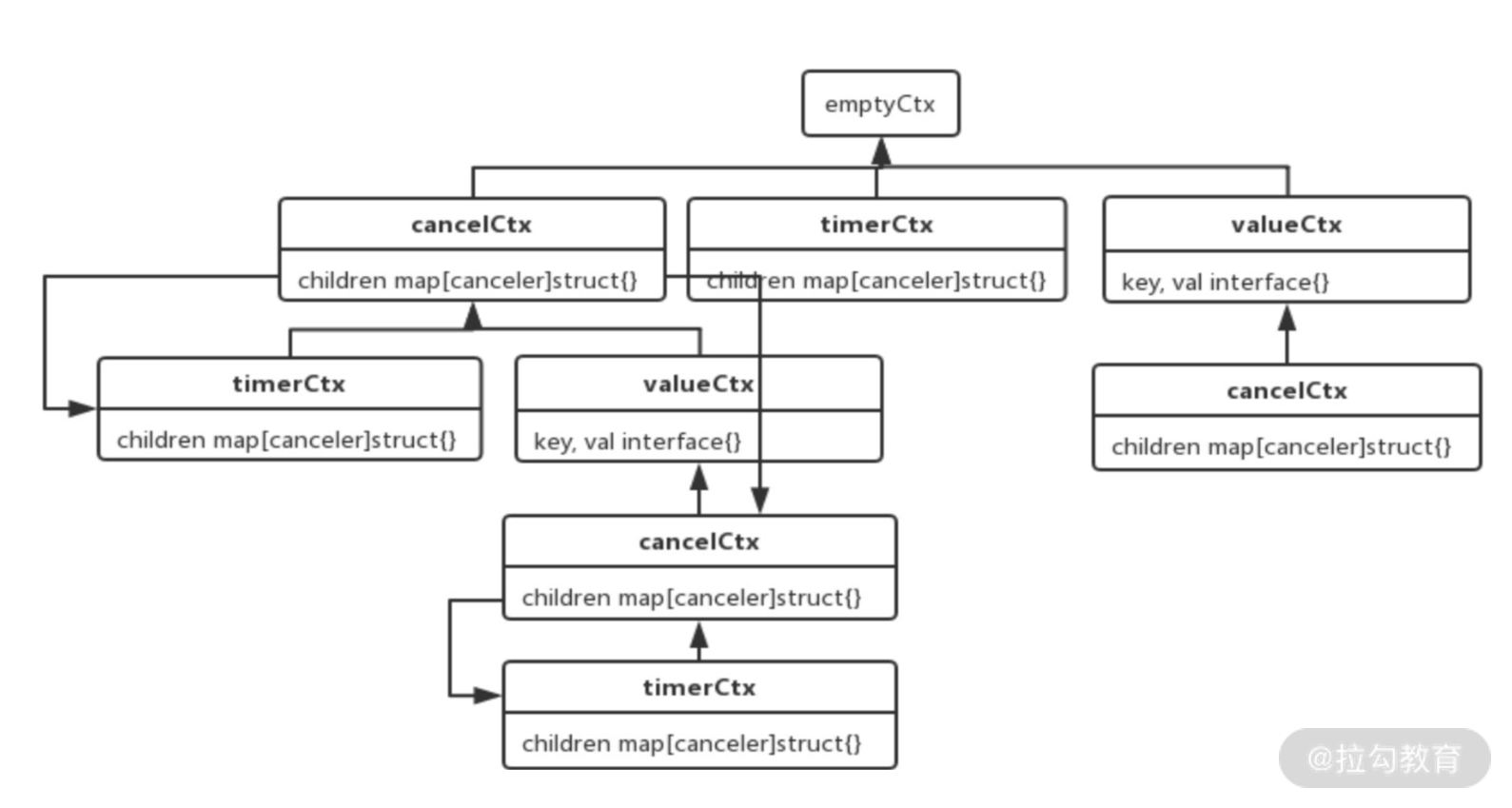
context.Background()获取一个根节点 Context。
Context 树要怎么生成呢?
- **
WithCancel(parent Context)**:生成一个可取消的 Context。- **
WithDeadline(parent Context, d time.Time)**:生成一个可定时取消的 Context,参数 d 为定时取消的具体时间。- **
WithTimeout(parent Context, timeout time.Duration)**:生成一个可超时取消的 Context,参数 timeout 用于设置多久后取消
- **
- **
- **
WithValue(parent Context, key, val interface{})**:生成一个可携带 key-value 键值对的 Context。
以上四个生成 Context 的函数中,前三个都属于可取消的 Context,它们是一类函数,最后一个是值 Context,用于存储一个 key-value 键值对。
指针
1 | func main() { |
获取一个变量的指针非常容易,使用取地址符 & 就可以
指针类型就是在对应的类型前加 * 号
指针类型非常廉价,只占用 4 个或者 8 个字节的内存大小。
通过 var 声明的指针变量还没有分配内存,因为这时候它仅仅是个变量,是不能直接赋值和取值的,它的值是 nil

解决方法:将一块内存地址
&m赋值给指针变量*p1
2
3
4var p *int
var m int
p = &m通过new创建的指针是存在内存地址的,可以直接赋值
var intP *int = new(int)
参数传递
严格来说,Go 语言没有引用类型,但是我们可以把 map、chan 称为引用类型,这样便于理解。除了 map、chan 之外,Go 语言中的函数、接口、slice 切片、指针都可以称为引用类型。
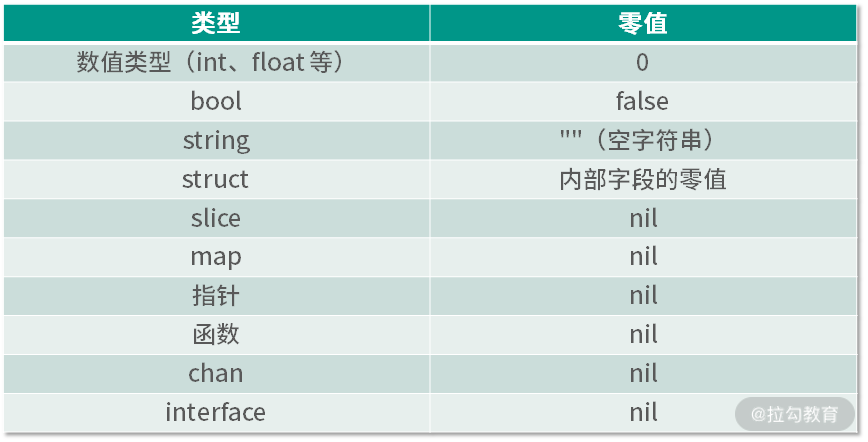
总结:
在 Go 语言中,函数的参数传递只有值传递,而且传递的实参都是原始数据的一份拷贝。
如果拷贝的内容是值类型的,那么在函数中就无法修改原始数据;
如果拷贝的内容是指针(或者可以理解为引用类型 map、chan 等),那么就可以在函数中修改原始数据。
内存分配
- 指针类型的变量如果没有分配内存,就默认是零值 nil,它没有指向的内存,所以无法使用,强行使用就会得到以上 nil 指针错误
- 对于值类型来说,即使只声明一个变量,没有对其初始化,该变量也会有分配好的内存。
- 两个关键函数:new和make
new
new 函数只用于分配内存,并且把内存清零,也就是返回一个指向对应类型零值的指针。new 函数一般用于需要显式地返回指针的情况,不是太常用。
make
make 函数只用于 slice、chan 和 map 这三种内置类型的创建和初始化,因为这三种类型的结构比较复杂,比如 slice 要提前初始化好内部元素的类型,slice 的长度和容量等,这样才可以更好地使用它们。
反射
reflect.Value和**reflect.Type**在 Go 语言的反射定义中,任何接口都由两部分组成:接口的具体类型,以及具体类型对应的值。比如 var i int = 3,因为
interface{}可以表示任何类型,所以变量 i 可以转为 interface{}。其中 Value 为变量的值,即 3,而 Type 为变量的类型,即 int。1
2
3i:=3
iv:=reflect.ValueOf(i)
it:=reflect.TypeOf(i)修改变量
要修改一个变量的值,有几个关键点:传递指针(可寻址),通过 Elem 方法获取指向的值,才可以保证值可以被修改,reflect.Value 为我们提供了 CanSet 方法判断是否可以修改该变量。
1
2
3ipv := reflect.ValueOf(&i)
ipv.Elem().SetInt(4)
fmt.Println(i)反射的三大定律
- 任何接口值
interface{}都可以反射出反射对象,也就是 reflect.Value 和 reflect.Type,通过函数 reflect.ValueOf 和 reflect.TypeOf 获得。 - 反射对象也可以还原为 interface{} 变量,也就是第 1 条定律的可逆性,通过 reflect.Value 结构体的 Interface 方法获得。
- 要修改反射的对象,该值必须可设置,也就是可寻址,参考上节课修改变量的值那一节的内容理解。
- 任何接口值
SliceHeader
在 Go 语言中,切片其实是一个结构体,定义如下:

SliceHeader 是切片在运行时的表现形式,它有三个字段 Data、Len 和 Cap。
- Data 用来指向存储切片元素的数组。
- Len 代表切片的长度。
- Cap 代表切片的容量。
优点
- 支持动态扩容
- 切片的本质是 SliceHeader,又因为函数的参数是值传递,所以传递的是 SliceHeader 的副本,而不是底层数组的副本。这时候切片的优势就体现出来了,因为 SliceHeader 的副本内存占用非常少,即使是一个非常大的切片,也顶多占用 24 个字节的内存,这就解决了大数组在传参时内存浪费的问题。
测试
- 测试文件以_test.go结尾
- 测试函数以Testxxx(xxx为测试函数名)开头
假设编写的函数在ch18/main.go中:go test -v ./ch18
- go test -v –coverprofile=ch18.cover ./ch18:得到一个单元测试覆盖率文件
基准测试
衡量代码的性能
函数必须以 Benchmark 开头
函数的签名必须接收一个指向 testing.B 类型的指针,并且不能返回任何值;
最后的 for 循环很重要,被测试的代码要放到循环里;
b.N 是基准测试框架提供的,表示循环的次数,因为需要反复调用测试的代码,才可以评估性能。
运行:
go test -bench=. ./ch18
计时方法

内存统计

并发基准测试

泛型
Go的泛型使用interface实现
- an approximation element
~Trestricts to all types whose underlying type is T: 代表底层类型是T - a union element
T1 | T2 | ...restricts to any of the listed elements: 代表或,类型列表之一。
1 | // 任意类型 any |