教程来自 极客时间《从0开始学微服务》
1 微服务发展历史
单体应用阶段
早期互联网公司的架构:
- LAMP(Linux + Apache + MySQL + PHP)
- MVC(Spring + iBatis/Hibernate + Tomcat)
特点:团队规模一般不超过5人
服务化思想
把原来整个大的项目粗略分为不同的业务模块,拆分出来进行独立部署,并以RPC接口的形式对外提供服务。这样原来的模块就会由进程内调用变为远程RPC调用,也就可以独立开发、测试、上线和运维,甚至交给不同的团队去做。
微服务阶段
相比于服务化,微服务拆分粒度更细,服务之间更加独立,并且由于拆分后的服务更多,需要有一个同一个管理平台去维护,需要做服务监控、服务追踪、服务治理等去管理
1.1 服务发布和引用
📌最常见的服务发布和引用的方式有三种:
- RESTful API
- XML配置
- IDL文件
1.1.1 RESTful API
主要被用作HTTP或者HTTPS协议的接口定义,即使在非微服务架构体系下,也被广泛采用。
服务提供者和消费者间通过HTTP协议进行交互,适合需要向其他业务部分提供服务或者给外网提供服务的场景
1.1.2 XML配置
这种方式的服务发布和引用主要分三个步骤:
- 服务提供者定义接口,并实现接口。
- 服务提供者进程启动时,通过加载server.xml配置文件将接口暴露出去。
- 服务消费者进程启动时,通过加载client.xml配置文件来引入要调用的接口。
服务提供者和服务消费者之间维持一份对等的XML配置文件,来保证服务消费者按照服务提供者的约定来进行服务调用。在这种方式下,如果服务提供者变更了接口定义,不仅需要更新server.xml,还需要同时更新client.xml。
适用场景:
- 私有RPC框架(性能要求高)
- 公司内部联系比较紧密的业务
1 |
|
1.1.3 IDL文件
通过一种中立的方式来描述接口,使得在不同的平台上运行的对象和不同语言编写的程序可以相互通信交流。
有两种最常用的IDL:
- Facebook开源的Thrift协议
- Google开源的gRPC协议。
1.2 注册中心
- 服务注册
- 服务发现
1.2.1 注册中心原理
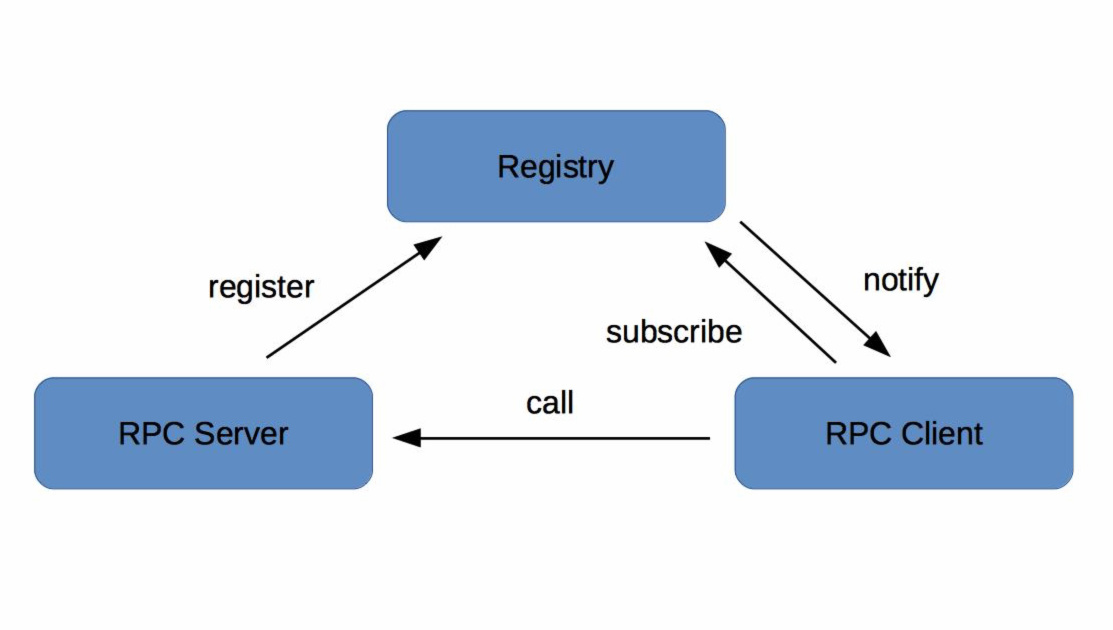
- RPC Server提供服务,在启动时,根据服务发布文件server.xml中的配置的信息,向Registry注册自身服务,并向Registry定期发送心跳汇报存活状态。
- RPC Client调用服务,在启动时,根据服务引用文件client.xml中配置的信息,向Registry订阅服务,把Registry返回的服务节点列表缓存在本地内存中,并与RPC Sever建立连接。
- 当RPC Server节点发生变更时,Registry会同步变更,RPC Client感知后会刷新本地内存中缓存的服务节点列表。
- RPC Client从本地缓存的服务节点列表中,基于负载均衡算法选择一台RPC Sever发起调用。
1.2.2 注册中心实现方式
注册中心API
- 服务注册接口:服务提供者通过调用服务注册接口来完成服务注册。
- 服务反注册接口:服务提供者通过调用服务反注册接口来完成服务注销。
- 心跳汇报接口:服务提供者通过调用心跳汇报接口完成节点存活状态上报。
- 服务订阅接口:服务消费者通过调用服务订阅接口完成服务订阅,获取可用的服务提供者节点列表。
- 服务变更查询接口:服务消费者通过调用服务变更查询接口,获取最新的可用服务节点列表。
- 服务查询接口:查询注册中心当前注册了哪些服务信息。
- 服务修改接口:修改注册中心中某一服务的信息。
1.2.2.2 集群部署
注册中心作为服务提供者和服务消费者之间沟通的桥梁,它的重要性不言而喻。所以注册中心一般都是采用集群部署来保证高可用性,并通过分布式一致性协议来确保集群中不同节点之间的数据保持一致。
以ZooKeeper为例,ZooKeeper集群中包含多个节点,服务提供者和服务消费者可以同任意一个节点通信,因为它们的数据一定是相同的。ZooKeeper的工作原理:
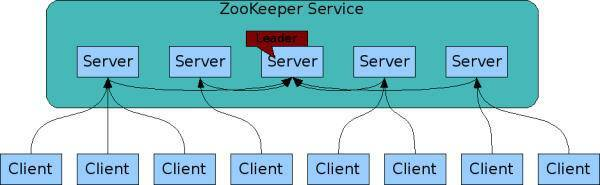
- 每个Server在内存中存储了一份数据,Client的读请求可以请求任意一个Server
- ZooKeeper启动时,将从实例中选举一个leader(Paxos协议)
- Leader负责处理数据更新等操作(ZAB协议)
- 一个更新操作成功,当且仅当大多数Server在内存中成功修改
通过上面这种方式,ZooKeeper保证了高可用性以及数据一致性
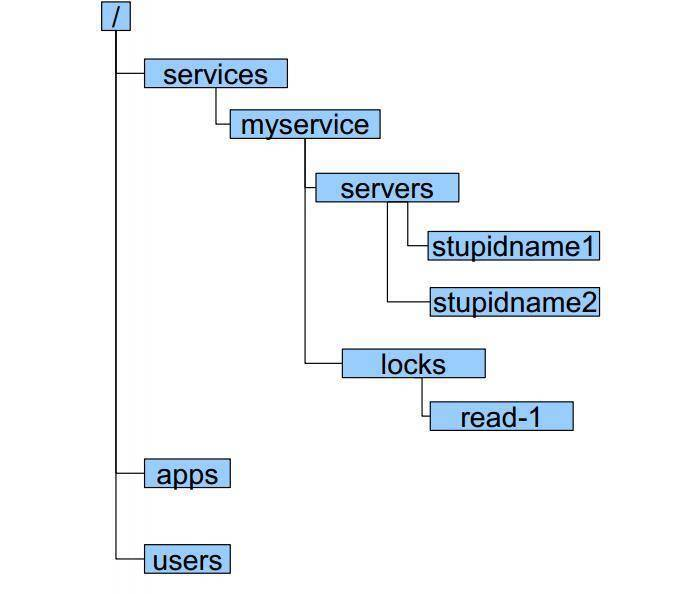
目录存储
还是以ZooKeeper为例,注册中心存储服务信息一般采用层次化的目录结构:
- 每个目录在ZooKeeper中叫作znode,并且其有一个唯一的路径标识。
- znode可以包含数据和子znode。
- znode中的数据可以有多个版本,比如某一个znode下存有多个数据版本,那么查询这个路径下的数据需带上版本信息。
服务健康状态检测
一旦注册中心探测到有服务提供者节点新加入或者被剔除,就必须立刻通知所有订阅该服务的服务消费者,刷新本地缓存的服务节点信息,确保服务调用不会请求不可用的服务提供者节点。
继续以ZooKeeper为例,基于ZooKeeper的Watcher机制,来实现服务状态变更通知给服务消费者的。服务消费者在调用ZooKeeper的getData方法订阅服务时,还可以通过监听器Watcher的process方法获取服务的变更,然后调用getData方法来获取变更后的数据,刷新本地缓存的服务节点信息。
1.2.2.5 白名单机制
在实际应用中,注册中心可以提供一个白名单机制,只有添加到注册中心白名单内的RPC Server,才能够调用注册中心的注册接口,这样的话可以避免测试环境中的节点意外跑到线上环境中去。
1.3 RPC远程调用
RPC协议的主要目的是做到不同服务间调用方法像同一服务间调用本地方法一样
由服务提供者给出业务接口声明,在调用方的程序里面,RPC框架根据调用的服务接口提前生成动态代理实现类,并通过依赖注入等技术注入到声明了该接口的相关业务逻辑里面。该代理实现类会拦截所有的方法调用,在提供的方法处理逻辑里面完成一整套的远程调用,并把远程调用结果返回给调用方,这样调用方在调用远程方法的时候就获得了像调用本地接口一样的体验。
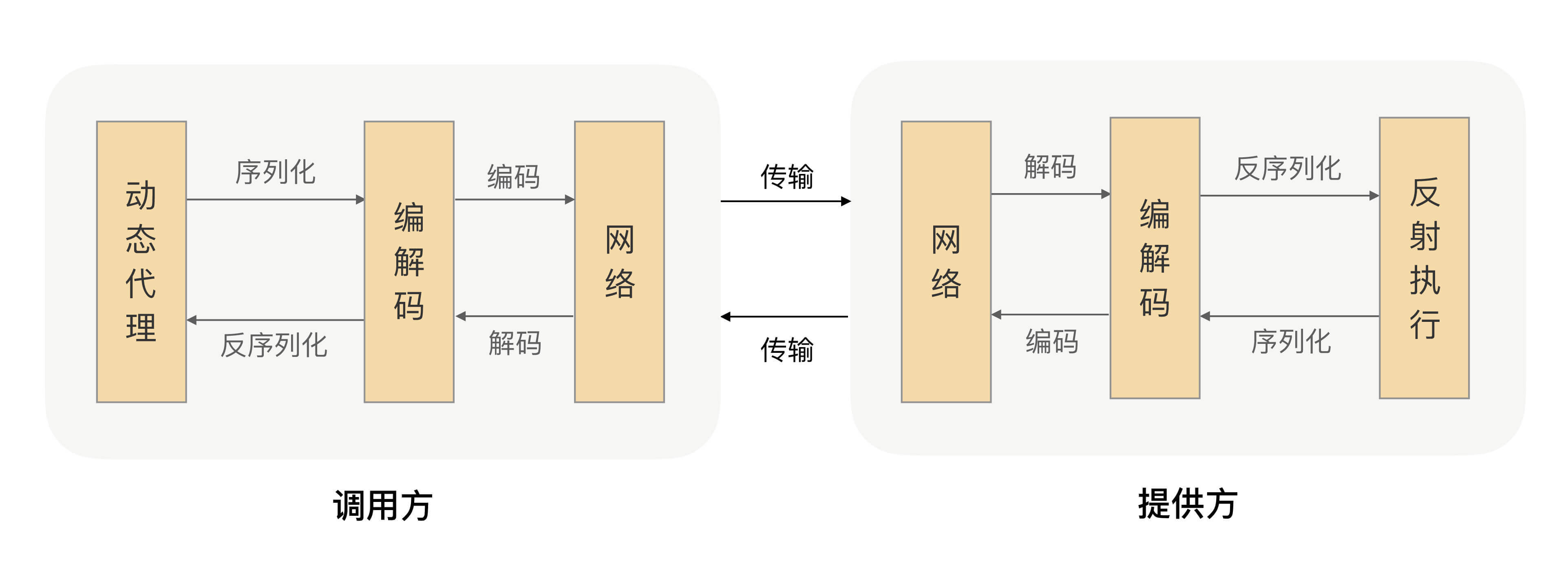
要完成一次RPC调用,就必须先建立网络连接。建立连接后,双方还必须按照某种约定的协议进行网络通信,这个协议就是通信协议。双方能够正常通信后,服务端接收到请求时,需要以某种方式进行处理,处理成功后,把请求结果返回给客户端。为了减少传输的数据大小,还要对数据进行压缩,也就是对数据进行序列化。
1.3.1 客户端和服务端如何建立网络连接?
HTTP通信
Socket通信
Socket通信是基于TCP/IP协议的封装,建立一次Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket;另一个运行于服务器端,称为ServerSocket。Socket通信的过程分为四个步骤:服务器监听、客户端请求、连接确认、数据传输。
1.3.2 服务端如何处理请求?
三种处理方式:
同步阻塞方式(BIO):客户端每发一次请求,服务端就生成一个线程去处理。
适用于连接数比较小的业务场景,这样的话不至于系统中没有可用线程去处理请求。这种方式写的程序也比较简单直观,易于理解。
同步非阻塞方式 (NIO):客户端每发一次请求,服务端并不是每次都创建一个新线程来处理,而是通过I/O多路复用技术进行处理。就是把多个I/O的阻塞复用到同一个select的阻塞上,从而使系统在单线程的情况下可以同时处理多个客户端请求。
适用于连接数比较多并且请求消耗比较轻的业务场景,比如聊天服务器。这种方式相比BIO,相对来说编程比较复杂。
异步非阻塞方式(AIO):客户端只需要发起一个I/O操作然后立即返回,等I/O操作真正完成以后,客户端会得到I/O操作完成的通知,此时客户端只需要对数据进行处理就好了,不需要进行实际的I/O读写操作,因为真正的I/O读取或者写入操作已经由内核完成了。
适用于连接数比较多而且请求消耗比较重的业务场景,比如涉及I/O操作的相册服务器。这种方式相比另外两种,编程难度最大,程序也不易于理解。
上面两个问题就是“通信框架”要解决的问题,常用开源通信框架有Netty、MINA等
1.3.3 数据传输采用什么协议?
- 开放协议:如最常用的Http
- 私有协议:如Dubbo
协议的作用就是“约定”。消费者按照约定对数据进行加密传输,提供者按照约定解码数据并进行处理,最后再加密发给消费者。
1.3.4 数据该如何序列化和反序列化?
常用的序列化方式分为两类:文本类如XML/JSON等,二进制类如PB/Thrift等,而具体采用哪种序列化方式,主要取决于三个方面的因素。
1.4 服务监控
服务监控的三个关键点:
1.4.1 监控对象
- 用户端监控
- 接口监控
- 资源监控
- 基础监控
1.4.2 监控指标
- 请求量
- 响应时间
- 错误率
1.4.3 监控系统原理
监控系统主要包括四个环节:数据采集、数据传输、数据处理和数据展示
数据采集
通常有两种数据采集方式:
- 服务主动上报
- 代理收集
数据传输
- UDP传输
- Kafka传输
数据处理
- 接口维度聚合
- 机器维度聚合
数据展示
如常见的曲线图、饼状图等等,以Dashboard方式展示给用户
补充:
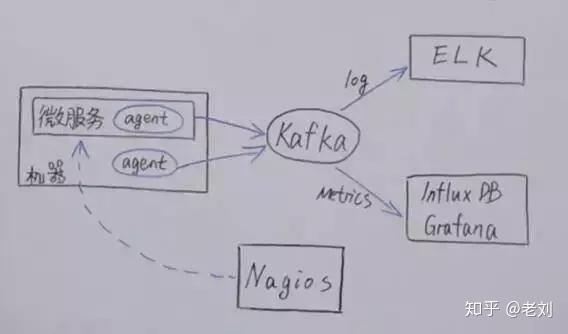
①监控架构
下面的图是大部分公司的一种监控架构图。每一个服务都有一个 Agent,Agent 收集到关键信息,会传到一些 MQ 中,为了解耦。
同时将日志传入 ELK,将 Metrics 传入 InfluxDB 时间序列库。而像 Nagios,可以定期向 Agent 发起信息检查微服务。
1.5 服务追踪
服务追踪可以跟踪记录用户的一次请求都发起了哪些调用,经过哪些服务处理,并记录每一次调用所涉及的服务的详细信息。在出现调用失败的时候,就可以第一时间定位到问题出现的地方。
1.5.1 服务追踪系统原理
服务追踪系统的鼻祖:Google发布的一篇的论文Dapper, a Large-Scale Distributed Systems Tracing Infrastructure,里面详细讲解了服务追踪系统的实现原理。它的核心理念就是调用链:通过一个全局唯一的ID将分布在各个服务节点上的同一次请求串联起来,从而还原原有的调用关系,可以追踪系统问题、分析调用数据并统计各种系统指标。
可以说后面的诞生各种服务追踪系统都是基于Dapper衍生出来的,比较有名的有Twitter的Zipkin、阿里的鹰眼、美团的MTrace等。
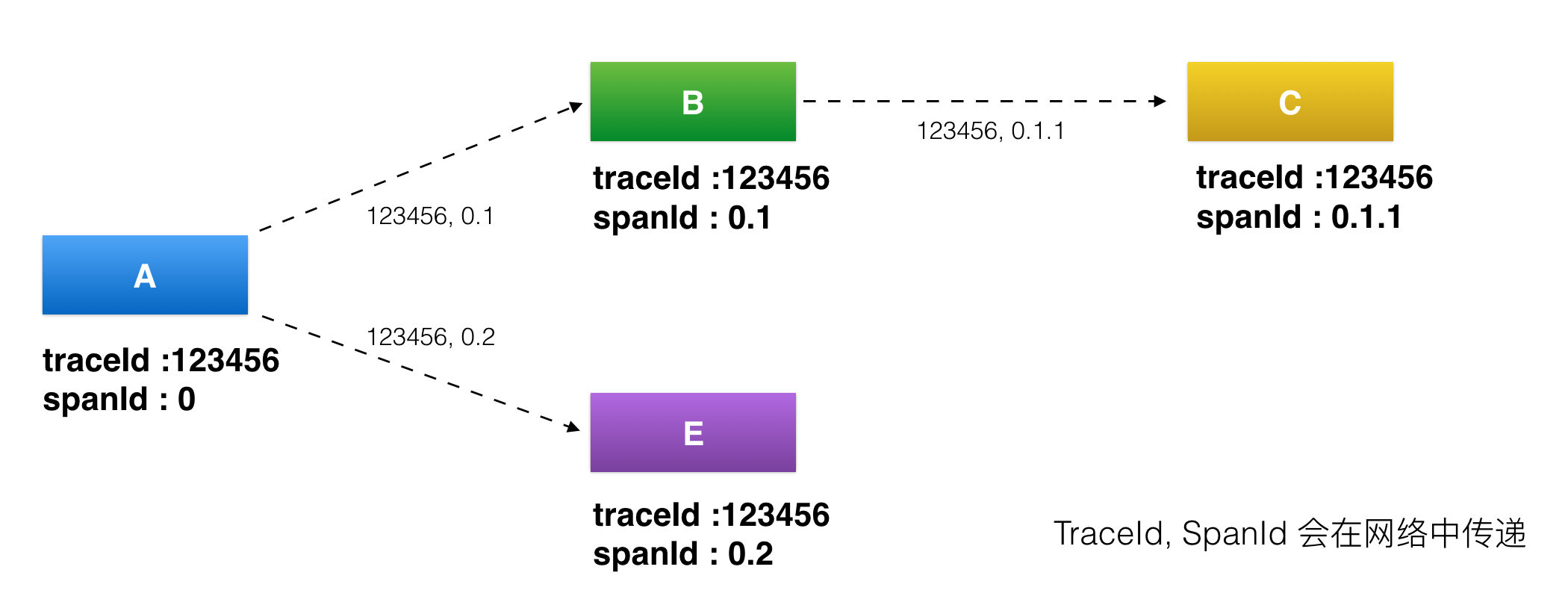
基本概念:traceId、spanId、annonation
traceId,用于标识某一次具体的请求ID。当用户的请求进入系统后,会在RPC调用网络的第一层生成一个全局唯一的traceId,并且会随着每一层的RPC调用,不断往后传递,这样的话通过traceId就可以把一次用户请求在系统中调用的路径串联起来。spanId,用于标识一次RPC调用在分布式请求中的位置。当用户的请求进入系统后,处在RPC调用网络的第一层A时spanId初始值是0,进入下一层RPC调用B的时候spanId是0.1,继续进入下一层RPC调用C时spanId是0.1.1,而与B处在同一层的RPC调用E的spanId是0.2,这样的话通过spanId就可以定位某一次RPC请求在系统调用中所处的位置,以及它的上下游依赖分别是谁。annotation,用于业务自定义埋点数据,可以是业务感兴趣的想上传到后端的数据,比如一次请求的用户UID。
1.5.2 服务追踪系统实现
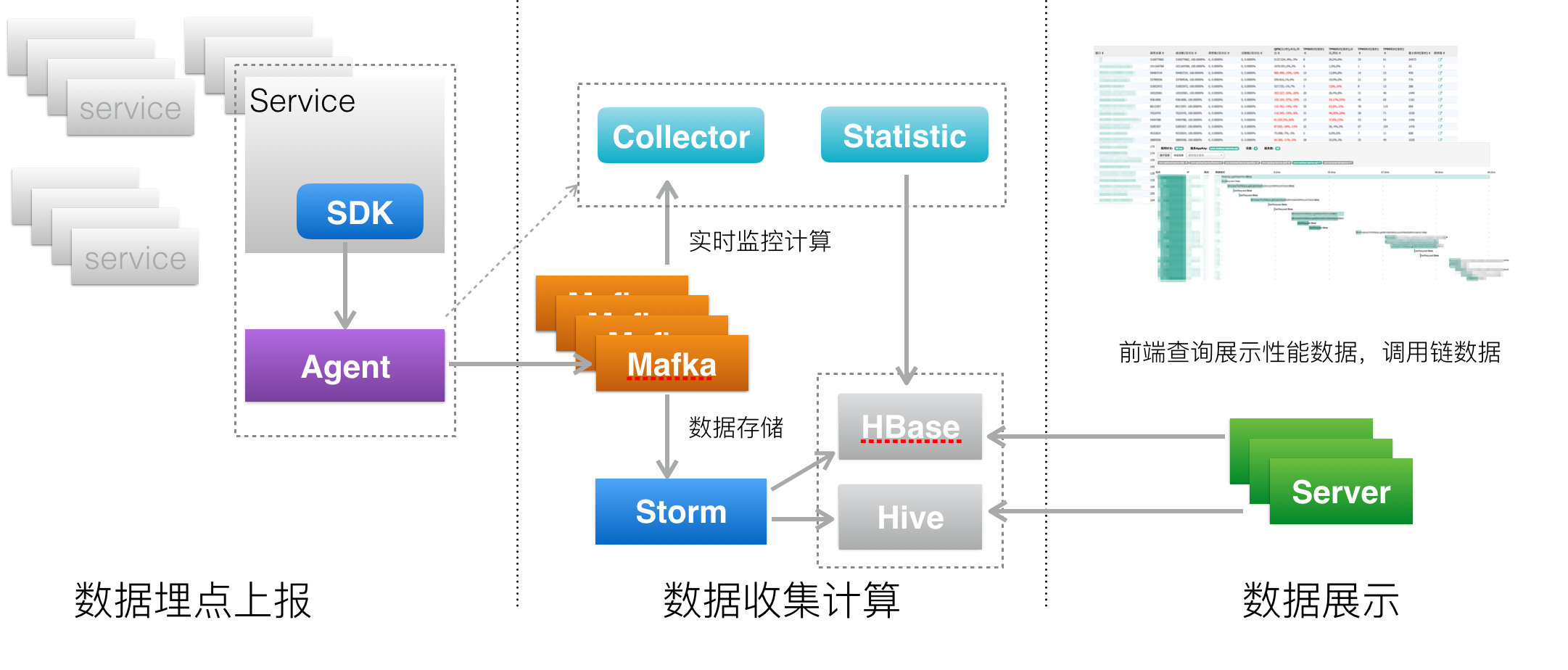
- 数据采集层,负责数据埋点并上报。
- 数据处理层,负责数据的存储与计算。
- 数据展示层,负责数据的图形化展示。
1.5.2.1 数据埋点的流程
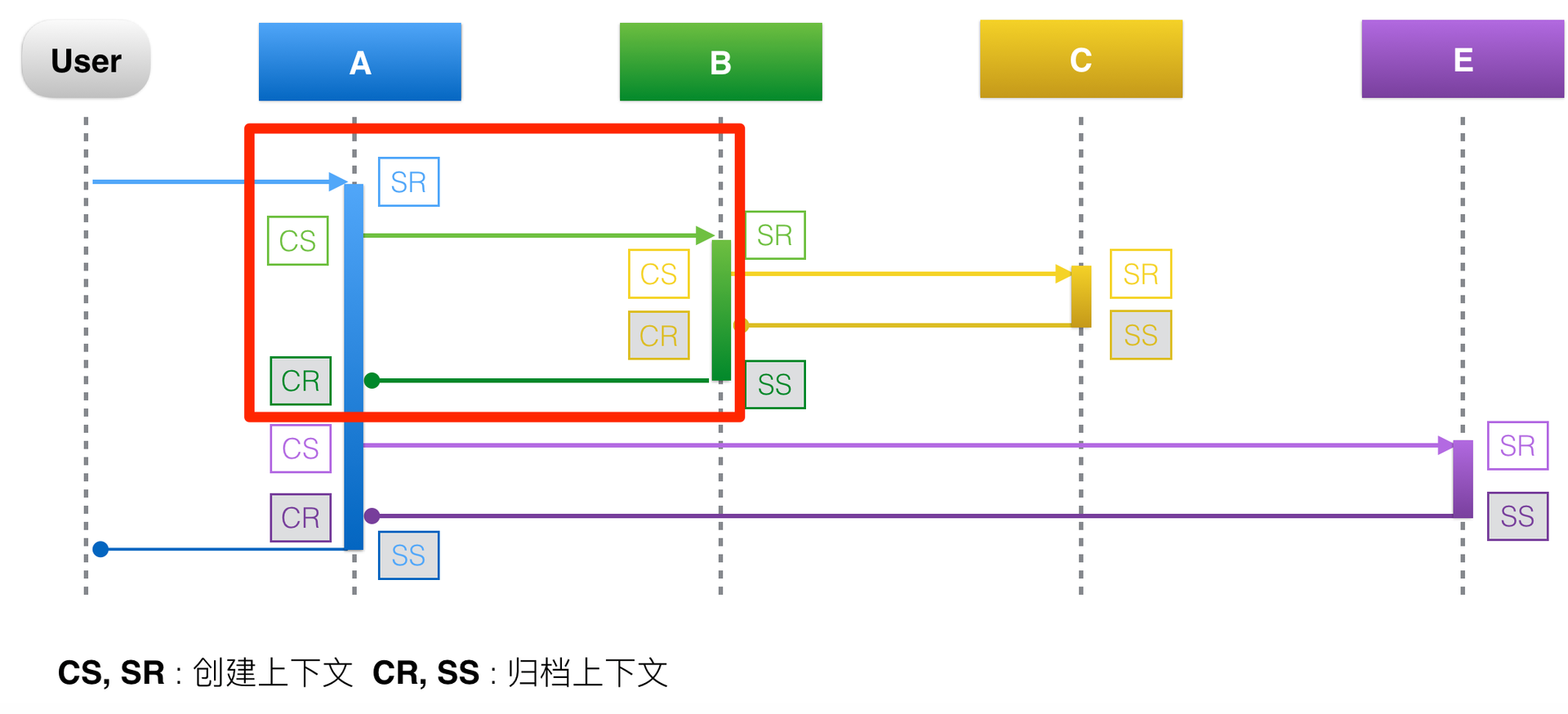
以红色方框里圈出的A调用B的过程为例,一次RPC请求可以分为四个阶段。
- CS(Client Send)阶段 : 客户端发起请求,并生成调用的上下文。
- SR(Server Recieve)阶段 : 服务端接收请求,并生成上下文。
- SS(Server Send)阶段 : 服务端返回请求,这个阶段会将服务端上下文数据上报,下面这张图可以说明上报的数据有:
traceId=123456,spanId=0.1,appKey=B,method=B.method,start=103,duration=38 - CR(Client Recieve)阶段 : 客户端接收返回结果,这个阶段会将客户端上下文数据上报,上报的数据有:
traceid=123456,spanId=0.1,appKey=A,method=B.method,start=103,duration=38
1.6 服务治理
服务调用出现问题:
- 注册中心宕机;
- 服务提供者有节点宕机;
- 服务消费者/提供者与注册中心之间的网络不通;
- 服务消费者和服务提供者之间的网络不通;
1.6.1 节点管理
- 注册中心主动摘除机制
- 服务消费者摘除机制
1.6.2 负载均衡
- 随机算法
- 轮询算法
- 最少活跃调用算法
- 一致性Hash算法
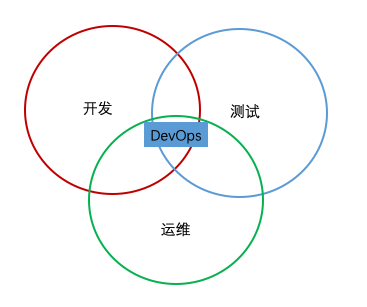
2 DevOps
传统业务流程:开发→测试→运维
DevOps:
- CI(Continuous Integration),持续集成。开发完成代码开发后,能自动地进行代码检查、单元测试、打包部署到测试环境,进行集成测试,跑自动化测试用例。
- CD(Continuous Deploy),持续部署/持续交付。代码测试通过后,能自动部署到类生产环境中进行集成测试,测试通过后再进行小流量的灰度验证,验证通过后代码就达到线上发布的要求了,就可以把代码自动部署到线上。